{kind=link}
Cloud offers many services and different types of configurations to design and architect an application. However, it is the Cloud architect responsibility to pick and choose right cloud services and configurations based on the requirements for architecting a cost efficient and reliable solutions.
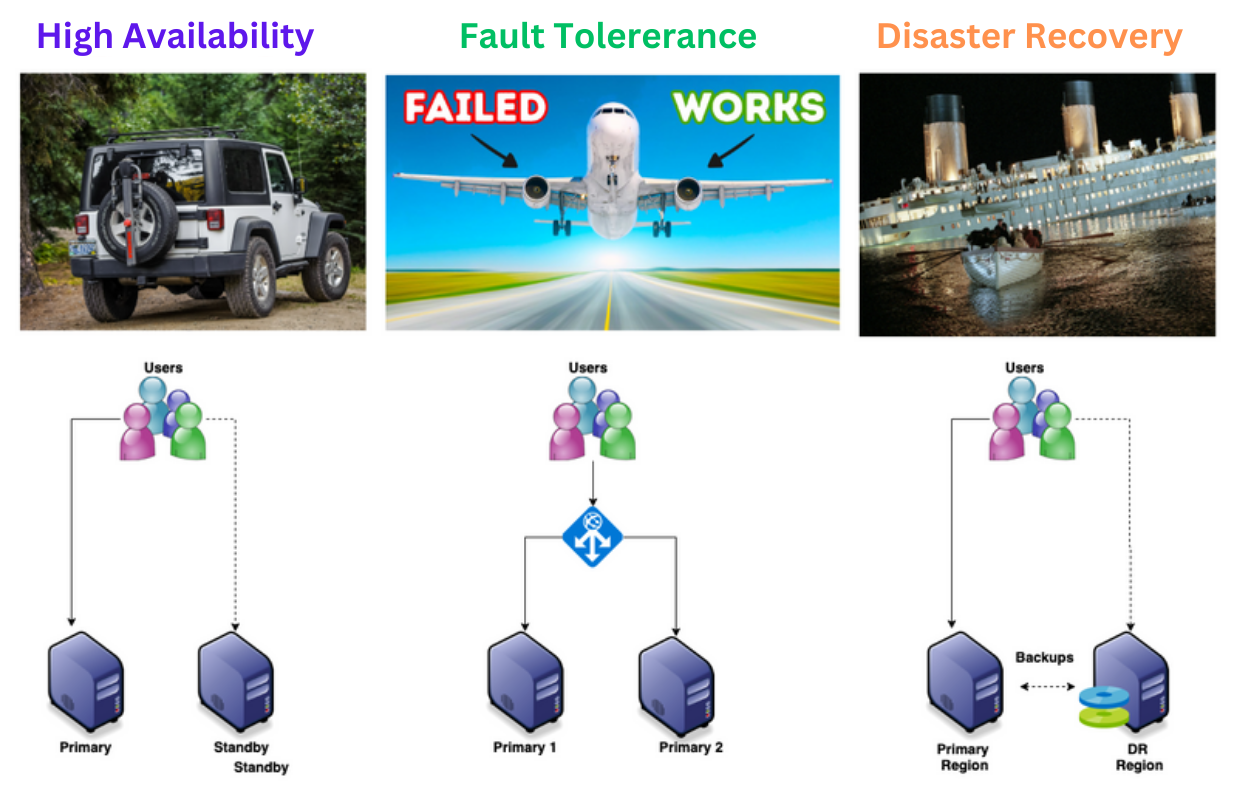
Often people get confused with the High Availability with Fault Tolerant and then Disaster Recovery with backup & restore. In this post we will aim to understand the primary difference between these concepts. This is very critical to understand before an architect design a cloud native application using different types of cloud services and configurations.
What is High Availability ?
It is defined as a characteristic of a system which aims to ensure an agreed level of operational performance, usually uptime, for a higher than normal period.
- As said in the above definition, high availability is basically ensuring that the system is available as per the agreed SLA and it is supposed to provide maximum uptime period.
- High Availability does not mean that the systems will not have failure and downtime. An HA system can have downtime but the systems should be designed to be up and running with minimal efforts in case of a failure. These efforts can be manual or automated.
- Highly Available systems are the systems which reduce the downtime periods and make the systems available as much as possible.
Read: How Application Virtualization works ?
Condition:
Consider the first example in the above diagram, The truck has a spare tire which will be useful if one of the tire has damage. This is a high available Truck. However, following conditions should still apply in order to be highly available
- New tire should be in good condition i.e it should have enough pressure and tire should not have any holes
- Trust should have the tools to replace the tire
- Finally, the driver should have the skills to replace the tire
If any of the above conditions does not meet, then the Truck is not highly available. Similarly in Cloud, in order to design Highly Available systems following conditions should be met
- The design should have primary and standby server with similar configurations i.e OS, application configurations, network and security settings etc.
- Application data should be accessible from both the servers.
- Administrator should have enough skillset and have access to the servers and configurations to make the necessary changes to bring up the application online as quickly as possible.
What is Fault Tolerance ?
It is the property that enables a system to continue operating properly in the event of the failure of one or more faults within some of its components. A fault-tolerant design enables a system to continue its intended operation, possibly at a reduced level, rather than failing completely, when some part of the system fails.
- Fault Tolerant system means that the system should not have any kind of downtime in the event of failure of one or more components.
- The application should still be accessible by the users atleast at a reduced level instead of complete shutdown.
- Fault tolerance is not same as high availability, fault tolerant design should prevent the downtime whereas high availability allows the downtime upto the agreed SLA limits.
Read: IAM Authorization vs Authentication
Conditions:
In the above example, you can see that aeroplanes are fault tolerant vehicles because they are designed to have two engines running at the same time and they prevent downtime. However, following conditions should still apply in order to be fault tolerant.
- Both the engines should be in good condition before take off.
- Aeroplane should be able to run on a single engine in case of other engine fails as long as possible.
- Pilot should have the skills to navigate the plane with the single engine until he finds a suitable place to land the aeroplane safely.
Similarly in cloud, in order to design a Fault tolerant system, following conditions should met.
- The design have redundant servers (two or more) with similar configurations in an active-active configurations mode possibly behind a load balancer.
- The system should prevent downtime if there is a failure in one of the server and until the failed server is recovered.
- Recovery of the failed server can be configured to be done automatically or manually.
- If it is manually, administrator should have enough skills to recover the server and replace the failed server with load balancer.
What is Disaster Recovery ?
It is a set of policies, tools and procedures to enable the recovery or continuation of vital technology infrastructure and systems following a natural or human-induced disaster. Disaster Recovery assumes that the primary site is not recoverable (at least for some time) and represents a process of restoring data and services to a secondary survived site, which is opposite to the process of restoring back to its original place.
- Disaster Recovery is not same as backup restore, this is the most misunderstood concepts.
- While they both server the same purpose of recovering the system to its original state there is a thin line difference.
- Disaster Recovery is the sequence of steps or process that need to be performed in case of a complete system failure or site failure which can due to a human errors or natural disasters. Where as backup/restore is used to restore single component or file restores.
- Often this recovery occurs by bringing the backup data from another site or location to the primary site.
- The another approach of DR is to point the DNS to the servers in the DR site. Both options are valid.
Read: Business Continuity and Disaster Recovery
Condition:
Consider the above example from the famous Titanic movie. Titanic has thousands of passengers and the ship is designed to have rescue boats and life jackets in case of a disaster.
- Rescue boats should be available for all the passengers and they should be good condition if the ship has failure and it is not repairable.
- Rescue boats should be easily accessible to the passengers.
- Captain of the ship and ship crew should be trained on how to use the rescue boats and the process to release the boats to prevent panic and accidents.
Similarly in cloud, in order to design a DR compatible systems following conditions should apply
- The systems must be designed to take the backup of the applications data and configurations in regular intervals.
- Document the sequence of steps that need to be performed in case of a recovery i.e first recover database and then the application components etc.
- Ensure the backup frequencies and retention settings are mapped to the required RTO and RPOs.
- Perform regular DR drills to ensure the steps are process are correct if the systems configurations are changed often.
HA vs FT vs DR :
Here is the table summarizing the key difference between High Availability, Fault Tolerant and Disaster Recovery.
HA and FT are mainly focused on preventing or minimizing downtime at the system level, ensuring continuous operation despite individual component failures. Whereas DR deals with recovering from larger-scale disasters that affect the entire system, aiming to restore functionality within an acceptable timeframe.
| Feature | High Availability (HA) | Fault Tolerance (FT) | Disaster Recovery (DR) |
| Focus | Minimize downtime | Prevent downtime completely | Recover from major outages |
| Scope | Individual component failures | Individual component failures | Large-scale disruptions |
| Examples | Redundancy, failover | Data replication, locking | Backups, DR plans |
| Goal | “Five nines” uptime | Continuous operation | Restore critical functions |
As a cloud architect, consider these principles when designing resilient systems. By implementing a combination of these strategies, organizations can create a robust and resilient IT infrastructure that can withstand various challenges and continue to deliver critical services with minimal disruption.