Generative AI (GenAI), particularly large language models (LLMs), relies heavily on a hidden language known as vector embeddings. These are mathematical constructs that capture the essence of the data in a form that machines can understand and process. The journey begins with understanding vectors – mathematical entities with both direction and magnitude. In AI, vectors become arrays of numbers representing data features.
This blog post delves into the world of these numerical representations, exploring their role in GenAI, functionalities, practical applications, and best practices for their utilization.
1. Vector Embeddings Introduction
What is a Vector?
- A vector is a mathematical entity that has both magnitude and direction. In the context of machine learning and AI, a vector is an array of numbers. These numbers, or coordinates, represent features or attributes of the data.
- For example, consider a simple 2D space with two features: height and weight. A person could be represented as a vector like this: [height, weight].
Read: Introduction to Generative AI
Vectorization
- Vectorization is the process of converting data into vector form. This involves extracting the relevant features from the data and representing them as coordinates in a vector.
- For instance, in Natural Language Processing (NLP), words in a sentence can be vectorized into a sequence of numbers, each representing a specific word or a group of words. Vectorization of “apple”: [0.8, -0.2, -0.3].
Vector Embedding
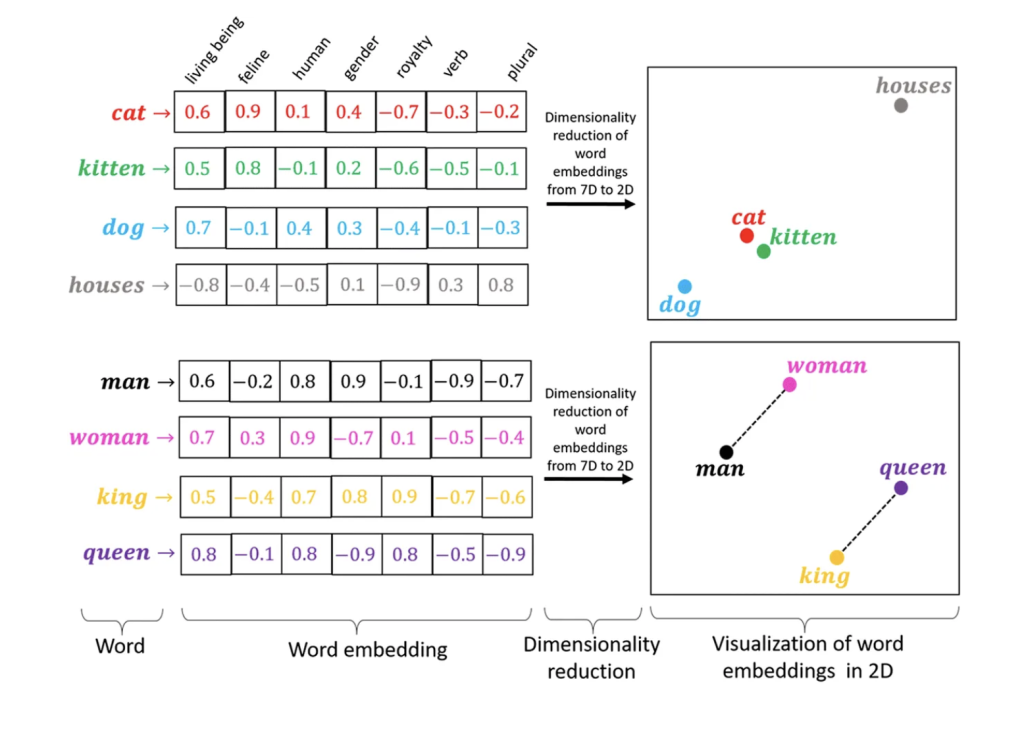
- Vector embedding is a type of representation where similar items are mathematically close together in the vector space. This is achieved by mapping the data to vectors in such a way that the geometric distance between the vectors corresponds to the semantic or functional similarity of the data.
- For example, in word embeddings, semantically similar words are mapped to vectors that are close to each other in the vector space. Instead of just treating words as letters, we convert them into numerical codes like [0.7, 0.2] for “king” and [0.6, 0.3] for “queen.” These numbers represent the words’ positions in a high-dimensional space, where similar words (like king and queen) end up closer together.
- This allows the AI model to understand the relationship between the words based on their positions, not just their spellings.
2. Core Concepts of Vector Embeddings
Dimensionality: The number of elements in a vector embedding is its dimensionality. Higher dimensions can capture more complex relationships but require more processing power. Finding the optimal dimensionality involves a trade-off between accuracy and efficiency.
Similarity: The distance between vectors in the high-dimensional space signifies their relative similarity. Vectors closer together represent concepts that are more similar semantically. Imagine word embeddings; “king” and “queen” would be closer than “king” and “banana.”
Read: Introduction to Large Language Models
Learning Techniques: Vector embeddings are not created manually. Algorithms like Word2Vec or GloVe (text), or Convolutional Neural Networks (CNNs) (images), analyze large datasets to automatically learn relationships between data points. These algorithms convert the data into numerical representations that capture the essence and semantic connections.
3. How Vectorization with Embeddings Works
- Data Preprocessing: Before vectorization, raw data undergoes cleaning and preparation. This includes tasks like tokenization for text, normalization for images, or feature extraction for audio.
2. Vector Embedding Techniques: Specific algorithms are used to convert preprocessed data into vector embeddings, depending on the data type.
- Example 1: Word Embeddings: Word2Vec analyzes large text corpora to learn word relationships. Each word is converted into a vector embedding, where similar words have similar representations in the high-dimensional space.
- Example 2: Image Embeddings: CNNs are commonly used. They identify and encode key features within an image (e.g., edges, shapes, colors) into a vector embedding. Images containing similar objects or scenes will likely have more similar embeddings.
3. Model Training: The generated vector embeddings are used to train GenAI models. These models learn to identify patterns and relationships within the vector space, enabling tasks like:
- Text Generation: Creating new text formats based on learned relationships between word embeddings.
- Image Classification: Identifying objects or scenes within an image by comparing the image embedding to known categories.
- Speech Recognition: Transcribing spoken language into text by analyzing the sequence of audio embeddings.
Benefits of Vector Embeddings in GenAI
Efficient Information Representation: Vectors allow GenAI models to process complex data in a compact and efficient manner. Imagine comparing entire sentences or images – vectors provide a more manageable way for models to work with the information.
Semantic Understanding: Vector embeddings capture the meaning and relationships between words, image features, or audio elements. This empowers GenAI models to develop a deeper understanding of the information they are processing.
Facilitate Model Training: Vector representations simplify the training process for GenAI models. By providing a structured format for data, models can learn more effectively and achieve higher levels of accuracy.
Types of Vector Embeddings
- Word Embeddings: These capture the meaning and relationships between words.
- Sentence Embeddings: Represent the meaning of entire sentences, often derived from word embeddings.
- Image Embeddings: Capture the salient features of an image, allowing models to recognize objects or scenes.
- Audio Embeddings: Audio data can be converted into a sequence of vectors representing audio features. GenAI models utilize these vectors for tasks like speech recognition.
Advanced Vector Embedding Techniques
- Contextual Embeddings: These capture the meaning of words by considering their context within a sentence, allowing for a more nuanced understanding compared to static word embeddings. Techniques like BERT and ELMo are prominent examples.
- Multilingual Embeddings: These aim to represent words from multiple languages in the same vector space, facilitating tasks like cross-lingual information retrieval and machine translation.
- Universal Embeddings: Representing various data modalities (text, images, audio) within a single vector space, enabling models to learn relationships across different data types.
4. Choosing the Right Vector Technique
The choice of vectorization technique depends on several factors:
1.Data Type: The type of data you’re working with (text, images, audio) dictates the appropriate technique. Common options include:
- Text: Word2Vec, GloVe, BERT (contextual)
- Images: Convolutional Neural Networks (CNNs)
- Audio: Mel-frequency cepstral coefficients (MFCCs)
2. Task Objective: Consider the specific task your GenAI model is designed for.
- Text similarity: Word2Vec or GloVe might be sufficient.
- Text generation requiring nuanced understanding: BERT or other contextual embeddings might be better suited.
- Image classification: Techniques like CNNs that capture visual features are preferred.
- Data Size and Computational Resources: Training complex embedding models can be computationally expensive. Consider the size of your dataset and available resources. Simpler techniques like Word2Vec might be preferable for smaller datasets or limited computational power.
Read: Introduction to Prompt Engineering
3. Desired Embedding Properties:
- Static vs. Contextual Embeddings: Choose static embeddings for tasks where word meaning is relatively constant, and contextual embeddings when meaning depends on surrounding context.
- Dimensionality: Experiment with different dimensionalities to find the optimal balance between accuracy and computational efficiency for your specific task.
5. Best Practices for Vector Embeddings in GenAI
Data Quality: The quality of your training data significantly impacts the quality of the resulting vector embeddings. Ensure the data is clean, relevant, and representative of the target domain for optimal performance.
Regular Updates: As language evolves and new information emerges, consider periodically retraining the vectorization models with fresh data to maintain accuracy and capture up-to-date relationships.
Monitoring and Evaluation: Continuously monitor the performance of your GenAI models and vector embeddings. Evaluate metrics relevant to your specific task (e.g., perplexity for text generation, accuracy for image classification) to identify areas for improvement.
Experimentation: Explore different vectorization techniques and hyperparameters to find the best configuration for your specific needs. This may involve trying different embedding sizes, training algorithms, or preprocessing methods.
Read: How to integrate GenAI into existing applications
6. Cloud Storage for Vector Datastores
- Cloud Storage Services like Google Cloud Storage, Amazon S3, or Azure Blob Storage offer cost-effective and scalable storage for large vector collections. However, these platforms might not provide functionalities specifically tailored for vector retrieval.
- Specialized databases like Amazon Pinpoint for Embeddings or Azure Cognitive Search offer optimized storage and retrieval functionalities based on vector similarity for Vector databases.
- These functionalities are particularly valuable for GenAI applications that rely heavily on searching and comparing vectors. Consider factors like scalability, query performance, and integration with your chosen cloud platform when selecting a vector database.
Vector embeddings serve as a cornerstone in GenAI, acting as the hidden language for models to communicate and process information. By employing various vectorization techniques with appropriate embeddings, adhering to best practices for data quality and model evaluation, and utilizing appropriate cloud storage solutions, developers can unlock the full potential of GenAI. As research progresses, vector embeddings are expected to play an even more significant role in shaping the future of AI, fostering advancements in areas like natural language processing, computer vision, and multimodal learning.
7. Summary and Conclusion
Vector embeddings are fundamental to Generative AI. They transform raw data like words, images, or audio into numerical representations that capture the meaning and relationships between data points. This allows Generative AI models to process information efficiently and understand the nuances within the data. Different embedding techniques exist, including word embeddings, image embeddings, and more advanced contextual embeddings. Choosing the right technique depends on factors like data type, the desired task, and computational resources. Best practices such as using quality data, regular updates, and experimentation are key for optimal performance within GenAI applications.
Vector embeddings provide the bridge between the messy world of human language and the structured realm of machine learning. By translating complex concepts into a numerical language that AI models can understand, they unlock the true power of Generative AI. Their importance will only increase as we develop more sophisticated AI systems that need to grasp the nuances of language, images, and other data types. The ability to effectively create and utilize vector embeddings is a crucial skill for anyone pushing the boundaries of Generative AI.


{kind=link}