! Explore LLM architecture, training (supervised vs unsupervised), and their role as foundation models in NLP. See how LLMs power the future of Generative AI.){kind=link}
Language! It’s the tool we use to think, connect, and create. But what if machines could not just understand our language, but use it in astonishingly powerful ways? Enter Large Language Models (LLMs), the AI rockstars making waves in the field of natural language processing (NLP). In this blog post, delves into the technical architecture of LLMs, exploring their core components, training methodologies, and their role in generative AI applications.
1. Understanding basics of Machine Learning Models
Before we explore Large Language Models, we need to first understand the basic concepts on Machine learning models and how do machines learn. Large Language Models can leverage two primary learning paradigms – supervised and unsupervised learning.
Read: Introduction to Generative AI
- Supervised Learning: Imagine a student learning with a teacher’s guidance. Similarly, supervised learning models are trained on labeled datasets where each data point has a corresponding label (desired output). For instance, an LLM trained for sentiment analysis might be fed labeled reviews – positive or negative – to learn how to classify new reviews. A prominent example of a supervised learning model is the Support Vector Machine (SVM), which can be used to classify text data like sentiment analysis or spam detection.
- Unsupervised Learning: Imagine a student exploring a new subject on their own. Unsupervised learning models analyze unlabeled data to identify patterns and relationships. LLMs can be pre-trained using unsupervised learning on massive collections of text to develop a fundamental understanding of language structure and statistical relationships between words. This pre-trained model then serves as a foundation for subsequent supervised learning tasks. A well-known example of unsupervised learning is K-Means clustering, which can be used to group similar documents together based on their content.
- Foundation Models: Think of foundation models as pre-trained LLMs that act as a launching pad for specific tasks. These models are trained on vast amounts of unlabeled text data using unsupervised learning techniques. This pre-training allows them to capture the underlying structure and relationships within language. Subsequently, these foundation models can be fine-tuned for specific tasks using supervised learning with labeled datasets. This two-stage approach (unsupervised pre-training followed by supervised fine-tuning) is a hallmark of many LLM architectures. A popular example of a foundation model is BERT (Bidirectional Encoder Representations from Transformers), which can be fine-tuned for various NLP tasks like question answering or sentiment analysis.
2. Introduction to Large Language Models (LLMs)
Large Language Models (LLMs) are a category of foundation models trained on immense amounts of data, making them capable of understanding and generating natural language and other types of content to perform a wide range of tasks1. They are designed to understand and generate text like a human, in addition to other forms of content, based on the vast amount of data used to train them. LLMs can perform a wide range of language-related tasks, including:
- Generating text: Creating text that’s similar to human-written language, such as poems, code, scripts, emails, letters, etc.
- Translating languages: Converting text from one language to another accurately.
- Answering questions: Providing informative and relevant answers to questions posed in natural language.
- Summarizing text: Condensing long pieces of text into shorter summaries that capture key points.
- Classifying text: Categorizing text based on its content, style, or tone (e.g., sentiment analysis).
LLMs are a significant breakthrough in Natural Language Processing (NLP) and artificial intelligence, and are poised to reshape the way we interact with technology and access information.
Some famous examples of LLMs include Open AI’s Chat GPT-3 and GPT-4, which have garnered the support of Microsoft. Other examples include Meta’s Llama models and Google’s bidirectional encoder representations from transformers (BERT/RoBERTa) and PaLM models1. IBM has also recently launched its Granite model series on watsonx.ai, which has become the generative AI backbone for other IBM products like watsonx Assistant and watsonx Orchestrate.
3. Large Language Models (LLMs) Architecture:
At the heart of LLMs lies the transformer architecture, a powerful neural network specifically designed for natural language processing tasks. Unlike traditional neural networks that process information sequentially (word by word), transformers excel at analyzing relationships between words anywhere in a sequence simultaneously. This capability is fundamental to understanding the context and flow of language.
Read: Basics and Fundamentals of Generative AI
Here’s a deeper dive into the key components of the transformer architecture:
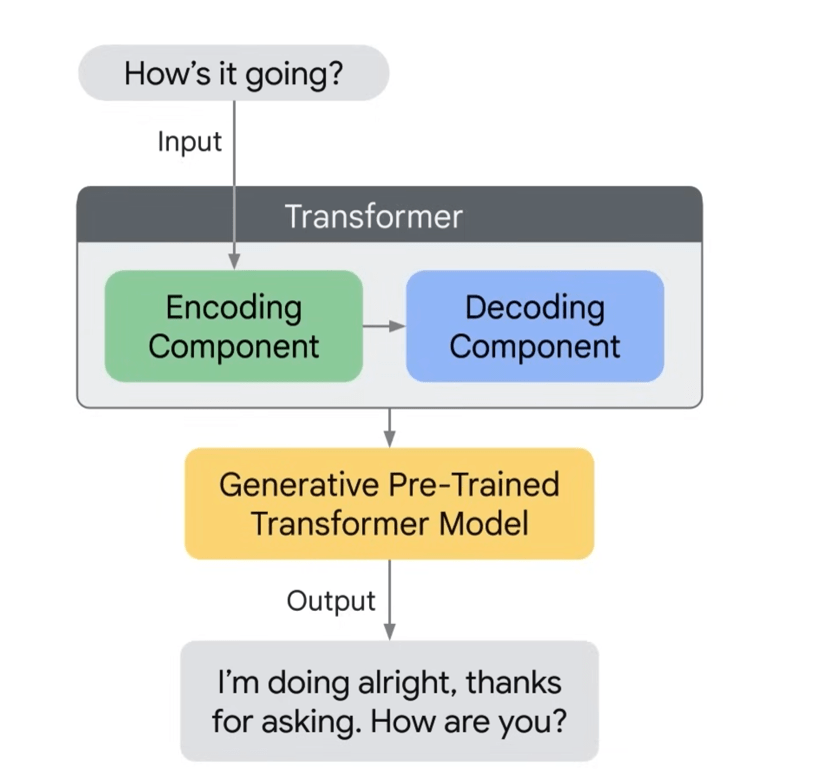
- Encoder-Decoder Architecture: Most LLMs leverage an encoder-decoder architecture, which can be likened to a translation system.
- Encoder: Imagine a translator analyzing a source language sentence. The encoder performs a similar function. It takes the input text (source language) and processes it to capture its meaning and the relationships between the words. It essentially creates a compressed representation of the input text, encoding the essential information.
- Decoder: The decoder then utilizes this encoded information from the encoder to generate the output text (target language). Similar to a translator formulating a sentence in the target language, the decoder uses its understanding of the encoded input to generate a new sequence of words, like translating a sentence or writing a continuation of a story.
- Encoder-Decoder Example: Imagine you want an LLM to write a poem based on a specific theme (e.g., love). The encoder would analyze the theme “love” and any additional information provided, capturing its essence. Then, the decoder would use this encoded understanding of love to generate a sequence of words that form a poem about love.
- Attention Mechanism: A key strength of transformers is the attention mechanism. Imagine a student focusing on specific sections of a textbook while studying a particular topic. The attention mechanism allows the LLM to do something similar. It focuses on specific parts of the input sequence that are most relevant to the current task, prioritizing important words and phrases. This targeted focus empowers the LLM to achieve a more nuanced understanding of the context within a sentence.
- How Attention Works: The attention mechanism assigns weights to different parts of the input sequence. Words that are deemed more relevant to the task at hand receive higher weights. By focusing on these high-weighted words, the LLM can grasp the crucial aspects of the input sequence and generate more relevant outputs.
- Positional Encoding: Unlike humans who can inherently understand the order of words in a sentence, machines require additional information. Positional encoding addresses this by injecting information about the relative position of each word within the sequence. This allows the LLM to grasp the order and context of words, even without relying solely on their sequential processing.
- Transformer Layers: Transformer models are typically comprised of multiple encoder and decoder layers stacked on top of each other. Each layer further refines the understanding of the input and refines the generation process. The information from the previous layer is passed on to the subsequent layer, allowing the model to progressively build a more comprehensive understanding.
Advantages of Transformer Architecture:
- Parallel Processing: Unlike traditional neural networks, transformers can analyze all parts of a sentence simultaneously due to their parallel processing capability. This significantly speeds up the processing of text data.
- Long-Range Dependencies: The attention mechanism allows the LLM to capture long-range dependencies within a sentence. Imagine understanding the connection between “but” at the beginning of a sentence and a clause later in the sentence. Transformers excel at considering these distant relationships between words, leading to a more comprehensive grasp of the meaning.
- State-of-the-Art Performance: The transformer architecture has become the foundation for many successful LLM models due to its ability to efficiently handle complex language tasks and achieve high accuracy.
By leveraging the power of the transformer architecture, LLMs can effectively analyze and process human language, unveiling the intricate relationships between words and sentences. This capability is what allows them to perform various tasks like generating different creative text formats of text content, translating languages, and writing different kinds of creative content.
4. Training Large Language Models (LLMs)
The success of LLMs relies on the massive amounts of text data they are trained on. This data can be vast and diverse, including books, articles, code, conversation logs, and even web pages. Here’s a simplified view of the training process:
Read: Skills required to build robust Gen AI applications in Cloud
- Data Preprocessing: The raw text data undergoes preprocessing steps like cleaning (removing irrelevant symbols), tokenization (breaking text into smaller units like words), and potentially converting words to numerical representations suitable for machine learning algorithms.
- Model Training: The preprocessed data is fed into the LLM architecture. Through a process called backpropagation, the model learns to adjust its internal parameters (weights and biases) to minimize the difference between its predictions and the desired outputs. Imagine a student adjusting their study approach based on their exam results. Similarly, backpropagation allows the LLM to refine its understanding of language patterns with each iteration. This iterative process continues until the model achieves a desired level of performance on a specific task.
5. How LLMs are used to create Generative AI applications
Generative AI refers to models that can create entirely new content. LLMs play a pivotal role in generative AI applications by providing the core text-generation engine. Here’s how LLMs fuel generative AI:
Core Text Generation Engine:
- LLMs, trained on massive text datasets, can grasp complex language patterns and statistical relationships between words. This empowers them to generate different creative text formats of text content, like poems, code, scripts, musical pieces, emails, letters, and even translate languages.
- Imagine a musician improvising a melody based on their knowledge of musical scales and chords. Similarly, LLMs can generate new text formats by drawing upon the vast knowledge they have acquired from the training data.
- A prominent example here is GPT-3 (Generative Pre-trained Transformer 3), a powerful LLM known for its ability to generate different creative text formats of content and answer open ended, challenging, or strange questions in an informative way.
Providing Context and Understanding:
- LLMs excel at understanding the context and flow of language. They can analyze the surrounding text and generate content that aligns with the overall theme, style, and intent.
- Imagine a writer who adjusts their writing style based on the target audience. Similarly, LLMs can adapt their text generation based on the context provided, ensuring the generated content is cohesive and relevant.
- An example application is Gemini (Google AI), a large language model that can be used for tasks like generating different creative text formats of content like poems or code, translating languages, and writing different kinds of creative content like informative email or creative marketing copy, all while considering the context provided in the prompt or surrounding text.
Sample-Based Generation:
- Generative AI models often rely on providing a starting point or “seed” to guide the content generation process. LLMs can then use this seed to create different creative text formats based on their understanding of language patterns.
- This is similar to how a musician might begin composing a piece with a starting melody or chord progression. The LLM can take this initial prompt and expand upon it to generate a complete story, poem, script, or even a musical piece (by predicting the next note in the sequence).
- A creative writing tool like Jasper (AI writing assistant) leverages this concept by allowing users to provide a starting sentence or paragraph, and the LLM engine within Jasper then generates different creative text formats of continuations based on the provided seed content.
Read: How GenAI services in cloud are revolutionizing application architectures
Fine-Tuning for Specific Tasks:
- While LLMs are powerful language models, generative AI applications can further fine-tune them for specific tasks. This involves training the LLM on additional data relevant to the desired outcome.
- Imagine a chef specializing in a particular cuisine. Similarly, fine-tuning an LLM on a dataset of movie reviews allows it to generate more relevant and nuanced reviews compared to training on generic text data.
- An example is a company using a generative AI system to write product descriptions. The LLM can be fine-tuned on a dataset of existing product descriptions and marketing copy, allowing it to generate descriptions that are not only grammatically correct but also align with marketing best practices.
Examples of Generative AI using LLMs:
- Chatbots: Generative AI powered by LLMs can create chatbots that hold natural conversations by understanding context, responding to questions in an informative way, and even generating different creative text formats of responses like jokes or poems depending on the situation.
- Content Creation: Generative AI systems can assist writers with content creation by generating different creative text formats of text content, writing different kinds of creative content like marketing copy or social media posts, and translating languages.
- Machine Translation: Traditional machine translation systems often struggle with nuances and context. Generative AI powered by LLMs can provide more fluent and accurate translations by considering the broader context and relationships between words.
- Creative Text Generation: Generative AI can use LLMs to generate different creative text formats of content like poems, scripts, musical pieces, and even computer code based on a starting prompt or theme. Imagine a songwriter using generative AI to brainstorm new lyrical ideas or melodies.
6. Different types of Large Language Models and their applications
While LLMs excel at understanding and generating text, their capabilities extend beyond simple text-to-text tasks. Here’s an overview of different LLM model types and their applications:
Text-to-Text:
- This core function allows LLMs to generate different creative text formats of text content, translate languages, write different kinds of creative content, and answer questions in an informative way.
- Examples include GPT-3 (Generative Pre-trained Transformer 3) is a powerful LLM known for its ability to generate different creative text formats of content and answer open ended, challenging, or strange questions in an informative way.
- Another example is Gemini (Google AI), a large language model that can be used for tasks like generating different creative text formats of content like poems or code, translating languages, and writing different kinds of creative content like informative emails or creative marketing copy, all while considering the context provided in the prompt or surrounding text.
Text-to-Speech:
- LLMs can be fine-tuned to convert written text into natural-sounding speech. This technology is used in applications like audiobooks, e-readers, and assistive technologies for visually impaired users.
- A prominent example is WaveNet (DeepMind), a generative model that can synthesize speech that closely resembles human speech patterns.
Text-to-Image:
- This emerging field leverages LLMs to generate images based on a textual description. Imagine describing a scene from a story, and an LLM generates a corresponding image. This technology has applications in creative design, product visualization, and generating illustrations for marketing materials.
- An example is DALL-E 2 (OpenAI), a powerful LLM that can create realistic and creative images from textual descriptions. The featured image of this post is created using DALL-E.
Text-to-Code:
- LLMs can be trained to translate natural language descriptions into programming code. This can be helpful for programmers who want to automate repetitive coding tasks or generate basic code structures from verbal instructions.
- An example is Github Copilot (powered by OpenAI’s Codex), an AI code completion tool that suggests lines or entire functions of code based on the surrounding context in a programmer’s editor.
Text-to-Video:
- This advanced application involves generating videos based on textual descriptions. While still under development, this technology has the potential to revolutionize content creation in fields like animation, marketing, and education.
- An example is Imagen Video (Google AI), a research project that explores generating short video clips from textual descriptions.
Text-to-3D Models:
- LLMs can be used to create 3D models from textual descriptions. This technology could be used in fields like product design, architecture, and virtual reality.
- An example is OpenAI Meshry, a system that can generate 3D point clouds (a collection of data points representing the surface of an object) from textual descriptions.
It’s important to note that these are just a few examples, and the field of LLM applications is rapidly evolving. As LLM architectures become more sophisticated and training data continues to grow, we can expect even more innovative applications that push the boundaries of human-computer interaction and content creation.
Read: How to identify GenAI usecases in existing applications
Large Language Models (LLMs) represent a transformative force in Natural Language Processing and generative AI. Their ability to understand and generate human-like text opens up a vast array of possibilities. As LLM architectures continue to evolve and training data becomes even more comprehensive, we can expect even more groundbreaking applications in various fields, revolutionizing the way we interact with machines and navigate the world of language.