{kind=link}
Quick Read
- ✅ Cloud reliability ensures applications continue operating despite hardware failures, software issues, network disruptions, or infrastructure outages by designing for resilience rather than assuming failures will never occur.
- ✅ High Availability (HA), fault tolerance, redundancy, backup, replication, and disaster recovery work together to minimize downtime and protect business-critical workloads across multi-cloud environments.
- ✅ AWS, Azure, Google Cloud, OCI, and IBM Cloud all provide architectural building blocks for resilient applications, but enterprise architects must design reliability into the solution rather than relying solely on cloud providers.
- ✅ Modern enterprise architectures distribute workloads across multiple Availability Zones, Regions, and sometimes multiple cloud providers to improve business continuity while balancing complexity, performance, and cost.
- ✅ AI and Agentic AI are transforming reliability operations by predicting failures, automating recovery workflows, optimizing capacity, and assisting engineers while operating within enterprise governance and approval processes.
Cloud Reliability & High Availability as a Foundational Cloud Building Block
In the previous lesson, you learned how cloud providers organize their global infrastructure using Cloud Regions, Availability Zones & Edge Locations. These components provide the physical foundation that allows organizations to deploy applications closer to users while improving resilience, scalability, and performance.
However, simply deploying workloads across multiple Regions or Availability Zones does not automatically make an application reliable. Enterprise systems must be intentionally designed to continue operating when hardware fails, networks become unavailable, or entire data centers experience outages.
Cloud reliability is achieved by combining resilient infrastructure with thoughtful architecture, operational excellence, automation, and continuous monitoring.
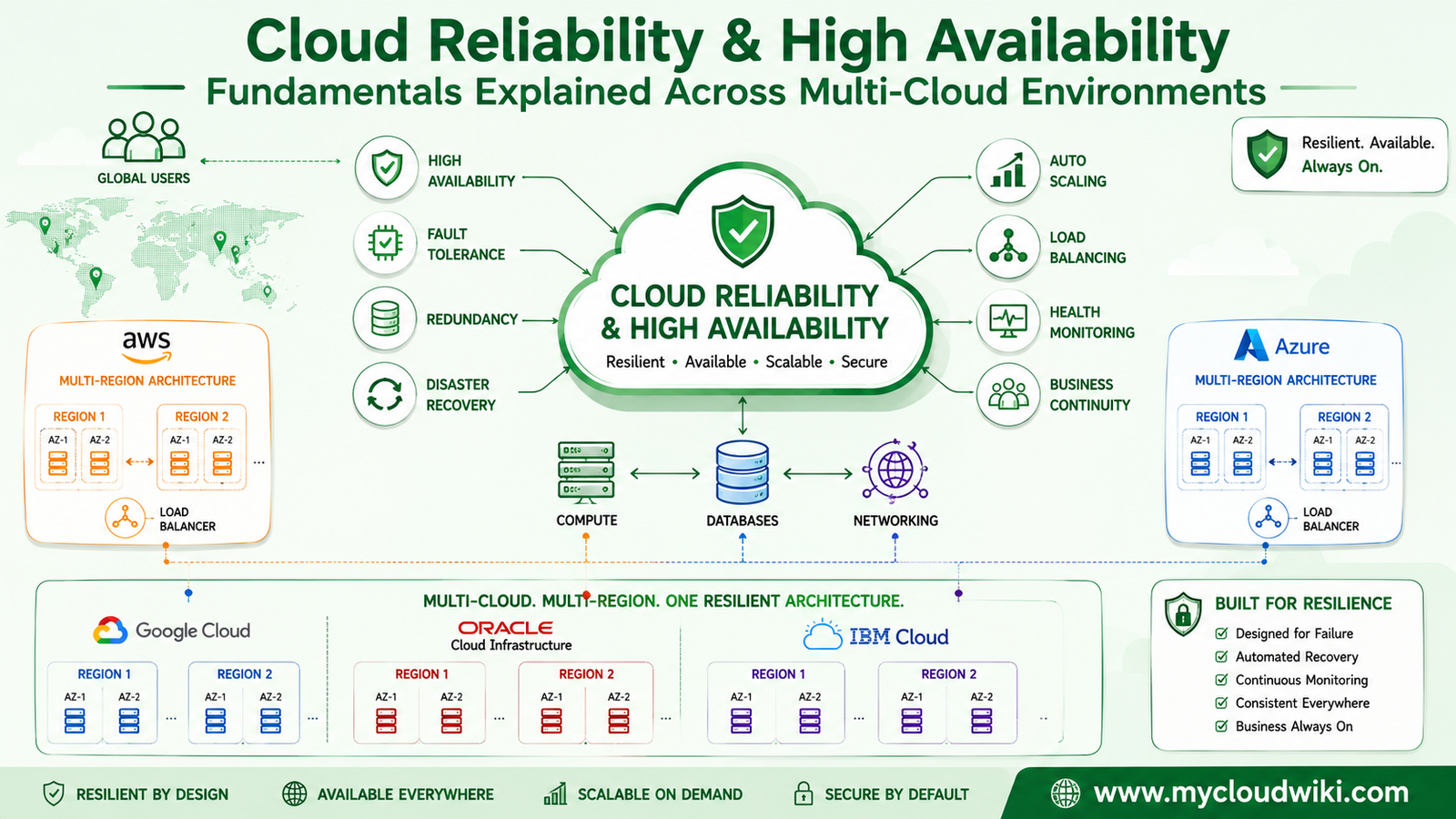
Cloud Reliability & High Availability Introduction
Every production system will eventually experience failures. Hardware fails, software contains defects, networks become congested, data centers lose connectivity, and cloud services occasionally become unavailable.
Modern cloud architecture accepts this reality rather than attempting to eliminate failures entirely.
Instead of asking:
“How do we prevent failures?”
Enterprise architects ask:
“How do we continue serving users when failures occur?”
Cloud Reliability and High Availability focus on designing applications that remain operational despite failures by using redundancy, fault isolation, automated recovery, and resilient deployment patterns.
Understanding these concepts is fundamental because they directly influence:
- Business continuity
- Customer experience
- Application uptime
- Disaster recovery
- Operational resilience
- Enterprise risk management
- Multi-cloud architecture decisions
Reliability is not achieved by purchasing more infrastructure—it is achieved through architecture, automation, operational discipline, and continuous improvement.
Architect’s Tip: Reliable applications are intentionally designed to expect failures. The goal is not to eliminate failures but to minimize their impact on users and business operations.
The following illustration introduces the core concepts of cloud reliability by showing how resilient architectures continue serving users even when infrastructure components fail.
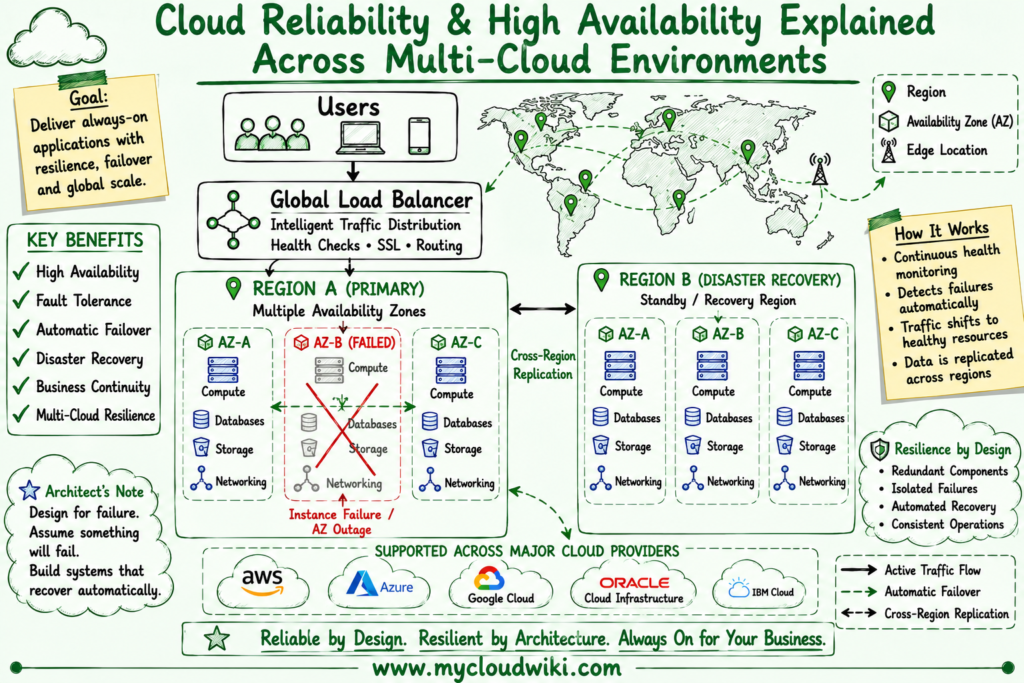
Reliable cloud architectures are built on the assumption that failures will happen. By distributing workloads across resilient infrastructure and automating recovery processes, organizations can continue delivering services even when individual components become unavailable.
Learning Objectives
After completing this lesson, you will be able to:
- Explain the concepts of reliability, availability, redundancy, fault tolerance, and resilience.
- Understand how enterprise applications achieve high availability across AWS, Azure, Google Cloud, OCI, and IBM Cloud.
- Compare backup, replication, disaster recovery, and failover strategies.
- Design workloads that continue operating during infrastructure failures.
- Understand how AI and Agentic AI improve enterprise reliability operations across multi-cloud environments.
Core Reliability Concepts
What Is Cloud Reliability?
Cloud reliability is the ability of an application or system to consistently perform its intended function despite hardware failures, software defects, infrastructure outages, or unexpected operational events.
Reliable systems continue delivering business services by detecting failures, isolating problems, and recovering quickly with minimal impact to users.
Cloud reliability depends on multiple disciplines working together, including:
- Resilient architecture
- High availability
- Fault tolerance
- Backup and recovery
- Disaster recovery
- Monitoring and observability
- Automation
- Operational excellence
Rather than relying on a single technology, reliability is achieved through a combination of design decisions, operational practices, and continuous improvement.
Architect’s Tip: Reliability begins during the architecture phase—not after an application is deployed. Designing for resilience from the beginning is far more effective than attempting to retrofit reliability later.
Key Characteristics of Reliable Cloud Systems
Reliable cloud platforms share several important characteristics:
- Redundant infrastructure to eliminate single points of failure.
- Automatic detection of unhealthy resources.
- Self-healing and automated recovery mechanisms.
- Load balancing across multiple instances.
- Fault isolation between infrastructure components.
- Continuous monitoring and alerting.
- Tested backup and disaster recovery procedures.
- Predictable operational processes.
These characteristics help ensure that applications remain available even when individual components fail.
Continue Learning: You’ll see how automation enables self-healing environments in Cloud Automation Fundamentals, where Infrastructure as Code and operational workflows reduce manual intervention during failures.
Reliability vs Availability
Although these terms are often used interchangeably, they represent different concepts.
- Reliability measures how consistently a system performs its intended function over time.
- Availability measures the percentage of time the system is accessible to users.
For example:
- An application may have excellent availability but still experience frequent performance problems.
- Another application may be extremely reliable but require scheduled maintenance windows that reduce overall availability.
Enterprise architects design systems that maximize both reliability and availability while balancing complexity and operational cost.
The following diagram illustrates the relationship between reliability, availability, redundancy, and recovery within a resilient cloud architecture.
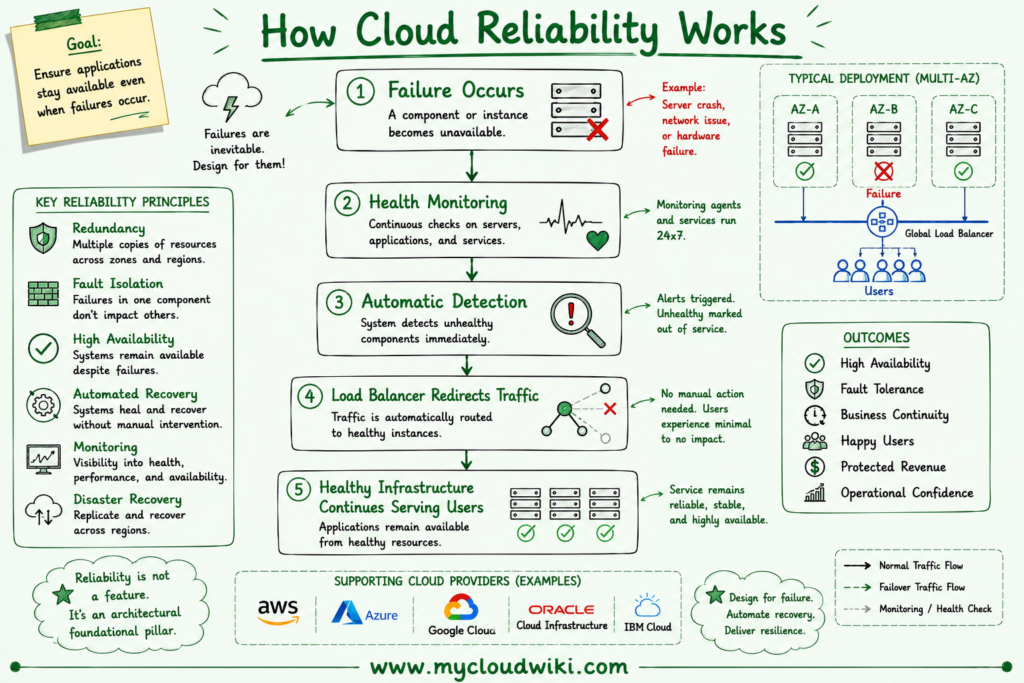
Failures are inevitable, but downtime is not. By combining redundancy, automated detection, health monitoring, and intelligent traffic routing, cloud platforms can continue delivering reliable services even when individual infrastructure components become unavailable.
Redundancy, Fault Tolerance and High Availability
Building reliable cloud applications requires more than simply deploying resources into the cloud. Enterprise architects combine several architectural principles that work together to minimize downtime and maintain business continuity during failures.
Although these concepts are closely related, each solves a different reliability challenge:
- Redundancy eliminates single points of failure by providing duplicate resources.
- Fault Tolerance enables systems to continue operating when components fail.
- High Availability (HA) minimizes downtime by automatically recovering from failures.
- Disaster Recovery (DR) restores services after major outages affecting entire sites or regions.
Understanding how these concepts complement each other is essential for designing resilient multi-cloud architectures.
Redundancy
Redundancy means deploying duplicate infrastructure components so that another resource can immediately take over if one fails.
Examples include:
- Multiple virtual machines serving the same application.
- Replicated databases.
- Multiple network paths.
- Duplicate storage systems.
- Multiple Availability Zones.
Redundancy reduces the risk of downtime by removing single points of failure throughout the architecture.
Fault Tolerance
Fault tolerance enables applications to continue operating without interruption even when individual infrastructure components fail.
Fault-tolerant systems typically include:
- Automatic workload distribution.
- Synchronous replication.
- Multiple active infrastructure components.
- Intelligent traffic routing.
- Automated health monitoring.
These architectures are commonly used for mission-critical applications where even brief downtime is unacceptable.
High Availability (HA)
High Availability focuses on minimizing downtime by automatically detecting failures and redirecting workloads to healthy infrastructure.
Typical High Availability designs include:
- Load balancers.
- Multiple Availability Zones.
- Health checks.
- Auto Scaling.
- Automated failover.
Unlike fault-tolerant systems, High Availability solutions may experience a brief interruption while failover occurs, but recovery is typically measured in seconds or minutes.
Disaster Recovery (DR)
Disaster Recovery prepares organizations for major infrastructure failures that affect entire data centers, Regions, or cloud providers.
A disaster recovery strategy commonly includes:
- Backup and recovery.
- Cross-region replication.
- Secondary production environments.
- Automated failover.
- Regular disaster recovery testing.
Disaster Recovery extends beyond infrastructure by ensuring that business operations can resume within agreed Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO).
Architect’s Tip: High Availability protects against infrastructure failures within a Region, while Disaster Recovery protects against larger-scale events such as regional outages or natural disasters. Enterprise applications often require both.
The following illustration compares redundancy, fault tolerance, High Availability, and Disaster Recovery to show how they work together within resilient cloud architectures.
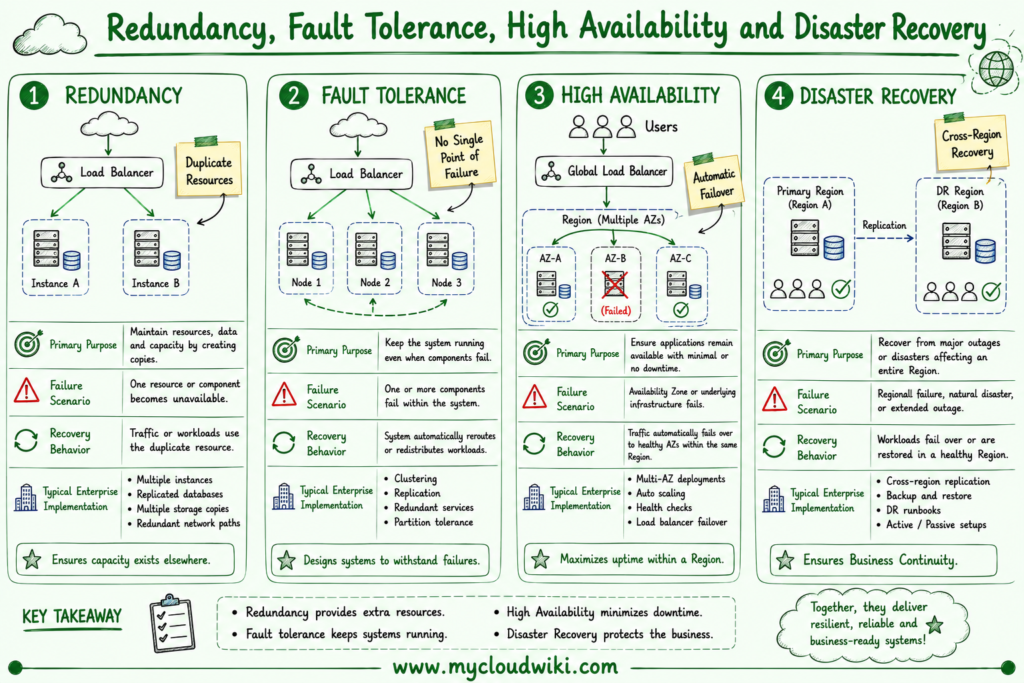
Each of these architectural principles addresses a different aspect of resilience. Enterprise solutions typically combine redundancy, High Availability, fault tolerance, and Disaster Recovery to achieve the level of reliability required by the business.
How Enterprise Applications Achieve High Availability
High Availability is achieved by combining multiple infrastructure components so that application services remain accessible even when individual resources fail. Rather than relying on a single server or database, enterprise applications distribute workloads across redundant infrastructure that can automatically recover from failures.
A typical highly available application includes:
- Multiple application instances.
- Load balancing across healthy resources.
- Multiple Availability Zones.
- Replicated databases.
- Shared or replicated storage.
- Automated health monitoring.
- Auto Scaling.
- Continuous backup and replication.
When one component becomes unavailable, traffic is redirected to healthy infrastructure with minimal disruption to users.
Architect’s Tip: High Availability is not a single service you enable. It is an architectural design pattern that combines compute, networking, storage, databases, monitoring, and automation into a resilient solution.
The following architecture demonstrates how multiple infrastructure components work together to maintain application availability during failures.
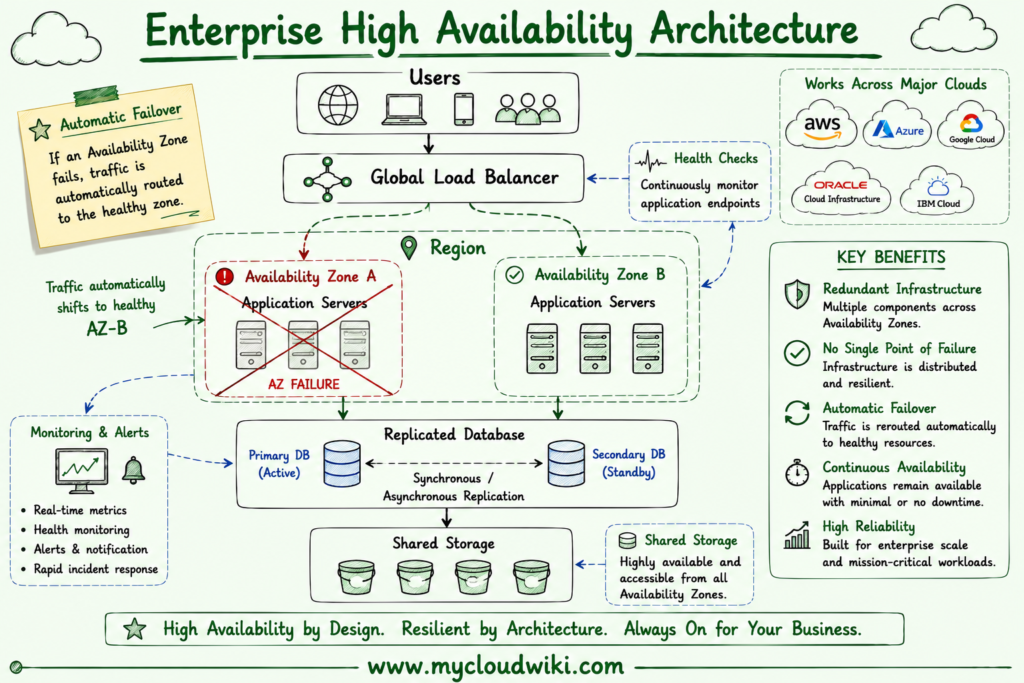
High Availability architectures eliminate single points of failure by distributing workloads across redundant infrastructure. The combination of load balancing, health monitoring, replication, and automated recovery enables applications to continue serving users despite individual component failures.
How to Choose the Right Availability Strategy
Not every application requires the same level of resilience. The appropriate availability strategy depends on business impact, recovery objectives, operational complexity, compliance requirements, and budget.
Enterprise architects balance these factors before selecting an availability model.
Consider the following when designing for reliability:
- Business criticality of the application.
- Acceptable downtime.
- Acceptable data loss.
- Regulatory and compliance requirements.
- Geographic distribution of users.
- Disaster recovery objectives.
- Operational complexity.
- Cost of implementing and maintaining resilience.
Higher availability generally requires additional infrastructure, automation, monitoring, and operational processes. The goal is to align the architecture with business needs rather than maximizing availability for every workload.
Continue Learning: Cloud Cost Optimization (FinOps) Fundamentals explains how architects balance resilience requirements with infrastructure costs to achieve the right business outcome.
The following decision matrix provides practical guidance for selecting an availability strategy based on common enterprise workload requirements.
Choosing the Right Availability Strategy
The following decision tree helps architects determine the most appropriate availability strategy based on business requirements.
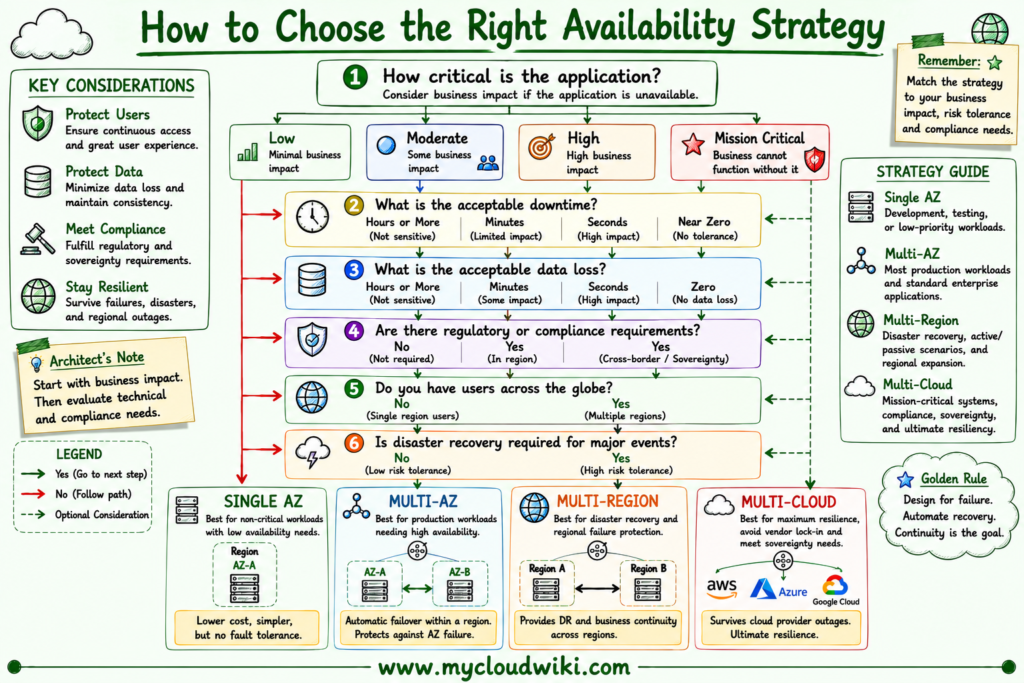
Selecting the right availability strategy is a business decision as much as a technical one. Enterprise architects evaluate business impact, recovery objectives, compliance requirements, operational complexity, and cost to design resilient solutions that meet organizational needs without introducing unnecessary complexity.
Cloud Reliability Across Major Cloud Providers
Although AWS, Azure, Google Cloud, OCI, and IBM Cloud use different service names and infrastructure implementations, they all provide the building blocks required to design highly reliable applications.
Rather than focusing on provider-specific features, enterprise architects standardize reliability principles across every cloud provider. This allows applications to achieve consistent resilience while reducing operational complexity in multi-cloud environments.
The common architectural principles include:
- Deploy workloads across multiple Availability Zones.
- Use multiple Regions for disaster recovery where appropriate.
- Continuously monitor application health.
- Automate failover and recovery workflows.
- Design for failure instead of assuming infrastructure is always available.
Architect’s Tip: Reliability should be measured by the user experience rather than infrastructure uptime alone. A highly available application is one that continues serving users even when individual components fail.
The following comparison shows how the major cloud providers support enterprise reliability through similar architectural capabilities.
Reliability Capabilities Across Major Cloud Providers
Although terminology varies, every provider offers comparable capabilities for building resilient cloud applications. Understanding the architectural concepts allows engineers and architects to design consistent reliability strategies regardless of the cloud platform.
The following comparison illustrates how the five major cloud providers implement the same reliability concepts using different managed services.
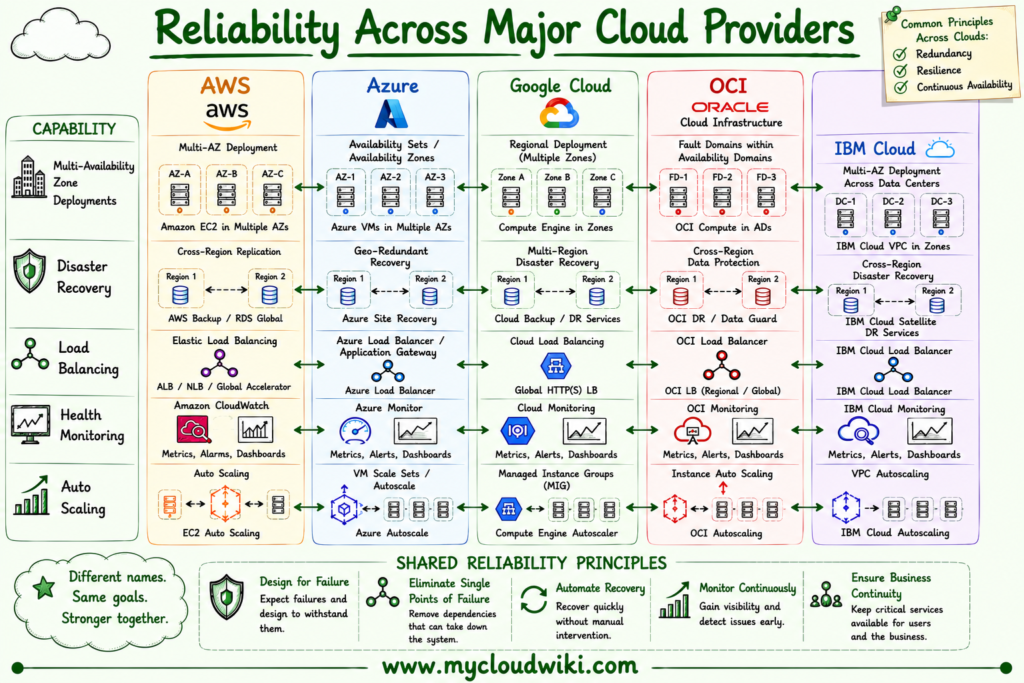
Enterprise reliability is built on architectural principles rather than cloud-specific implementations. Once these principles are understood, engineers can confidently apply them across AWS, Azure, Google Cloud, OCI, and IBM Cloud.
Cloud Reliability Through the Engineer and Architect Lens
Cloud engineers and enterprise architects both contribute to reliable cloud platforms, but their responsibilities differ. Engineers focus on implementing and operating resilient systems, while architects define the standards and patterns that enable enterprise-wide reliability.
Engineer Perspective
Cloud engineers are responsible for implementing and maintaining highly available infrastructure that keeps applications operational during failures.
Typical responsibilities include:
- Deploy workloads across multiple Availability Zones.
- Configure load balancers and health checks.
- Implement backup and replication.
- Configure Auto Scaling policies.
- Monitor application health.
- Troubleshoot availability issues.
- Execute disaster recovery procedures.
- Automate deployments and operational runbooks.
The engineer’s objective is to maintain reliable day-to-day operations while minimizing downtime.
Architect Perspective
Enterprise architects establish the standards and governance that enable reliable applications across multiple cloud providers.
Typical responsibilities include:
- Define enterprise reliability objectives.
- Establish high availability and disaster recovery standards.
- Select resilience patterns for different workloads.
- Define Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO).
- Standardize monitoring and operational practices.
- Design multi-region and multi-cloud architectures.
- Balance reliability, complexity, and cost.
- Ensure business continuity requirements are met.
Rather than focusing on individual infrastructure components, architects design enterprise-wide resilience strategies that engineering teams can implement consistently.
Continue Learning: Build Your First Multi-Cloud Architecture Mental Model connects reliability, networking, compute, storage, and security into a complete enterprise architecture.
The following illustration compares how engineers and architects approach cloud reliability from operational and strategic perspectives.
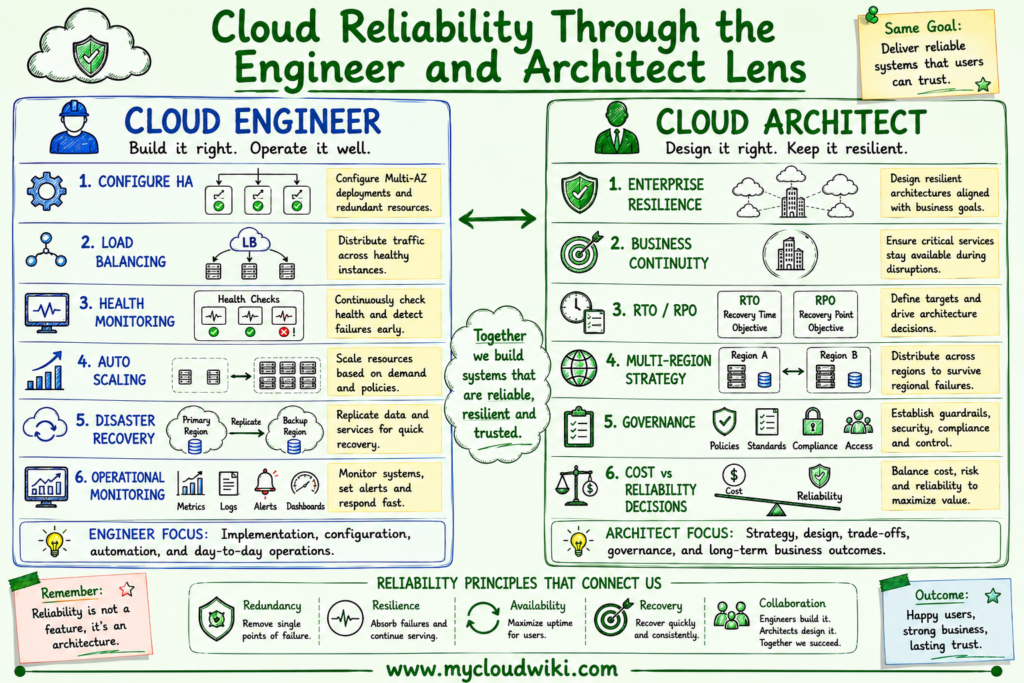
Engineers and architects work toward the same goal of delivering reliable services, but they contribute at different levels. Engineers implement resilience within individual workloads, while architects establish the enterprise standards that ensure reliability across applications, Regions, and cloud providers.
Multi-Cloud Reality Check
Building reliable applications across multiple cloud providers introduces additional design considerations beyond traditional high availability.
Enterprise organizations must account for:
- Different service availability across Regions.
- Provider-specific failover capabilities.
- Cross-cloud networking latency.
- Data replication across cloud providers.
- Regulatory and data residency requirements.
- Operational consistency across multiple platforms.
- Unified monitoring and incident response.
Rather than creating separate reliability strategies for each cloud, successful organizations establish common architectural principles that guide workload placement, disaster recovery, monitoring, and governance across every provider.
Cloud Reliability in Multi-Cloud Environments
Enterprise organizations increasingly use multiple cloud providers to improve resilience, reduce business risk, and support global operations. A well-designed multi-cloud reliability strategy focuses on standardization rather than treating each cloud as an isolated environment.
A typical enterprise reliability architecture includes:
- Multi-Availability Zone deployments.
- Multi-Region disaster recovery.
- Cross-cloud backup strategies.
- Centralized identity and governance.
- Unified monitoring and observability.
- Infrastructure as Code.
- Automated failover workflows.
- Consistent operational procedures.
By applying common resilience principles across AWS, Azure, Google Cloud, OCI, and IBM Cloud, organizations can improve business continuity while reducing operational complexity.
Architect’s Tip: Multi-cloud does not automatically improve reliability. The benefits come from thoughtful architecture, standardized operational practices, and regularly tested recovery procedures.
The following architecture illustrates how enterprise organizations design resilient applications across multiple cloud providers using standardized governance and operational practices.
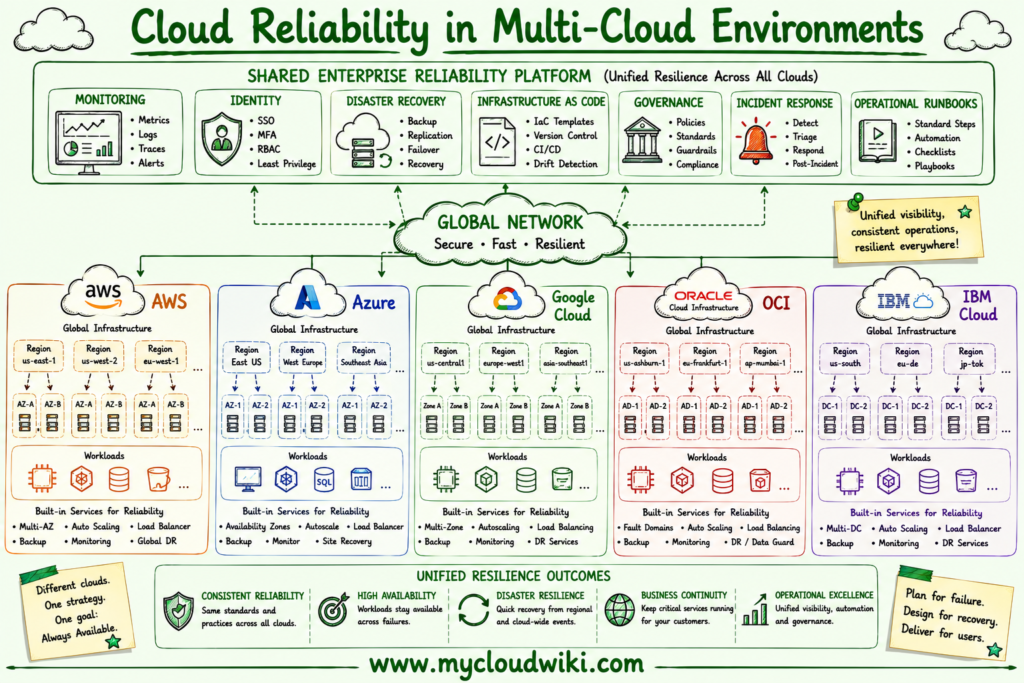
Cloud Reliability with Agentic AI
Modern cloud environments generate enormous amounts of operational data from applications, infrastructure, networking, databases, security platforms, and monitoring systems. As cloud environments grow across multiple Regions and cloud providers, manually monitoring and responding to every operational event becomes increasingly difficult.
Artificial Intelligence is helping cloud operations teams improve reliability by analyzing telemetry, identifying anomalies, predicting failures, and recommending corrective actions before users are affected.
Agentic AI extends these capabilities by executing approved operational workflows under enterprise governance. Instead of simply alerting engineers about a potential issue, an AI agent can initiate predefined recovery procedures while maintaining human oversight and auditability.
Common enterprise use cases include:
- Predicting infrastructure failures before they occur.
- Detecting application performance degradation.
- Recommending optimal workload placement.
- Automating incident response workflows.
- Executing disaster recovery runbooks.
- Optimizing Auto Scaling policies.
- Identifying reliability risks across multiple cloud providers.
- Assisting Site Reliability Engineering (SRE) teams during production incidents.
Although AI significantly improves operational efficiency, organizations must continue enforcing governance, approval workflows, security controls, and human accountability for critical infrastructure decisions.
Architect’s Tip: AI should help engineers respond faster—not make uncontrolled production decisions. Enterprise governance, approval workflows, and audit logging remain essential components of reliable cloud operations.
The following illustration demonstrates how AI and Agentic AI help enterprise operations teams maintain reliable cloud platforms across multiple cloud providers.
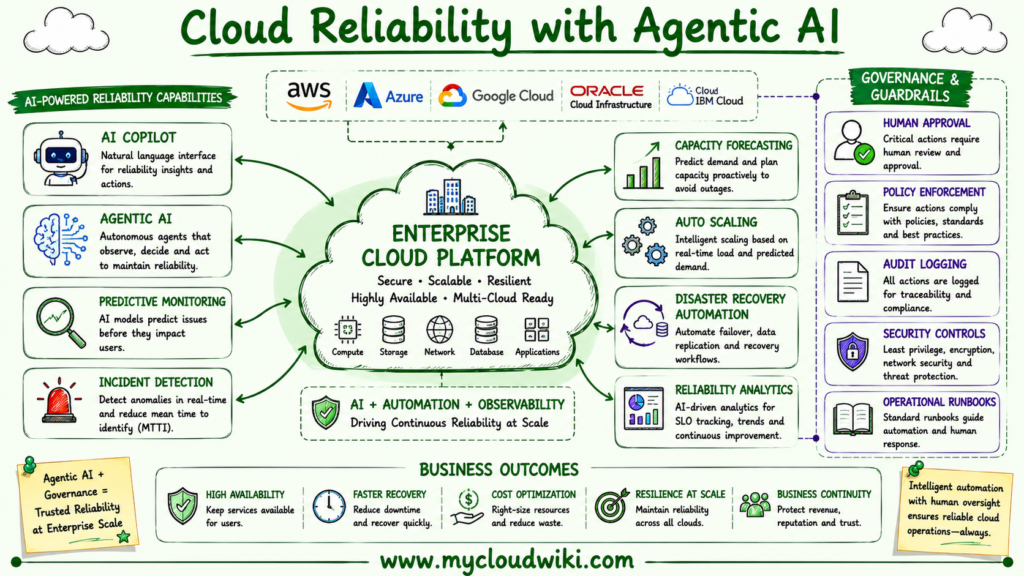
AI is becoming an important operational partner for reliability engineering by helping organizations predict failures, automate routine tasks, and improve incident response. However, resilient cloud platforms still depend on sound architecture, disciplined operations, and strong governance.
Well-Architected Multi-Cloud Reliability Strategy
Designing reliable cloud platforms requires more than deploying redundant infrastructure. Enterprise organizations should establish consistent reliability standards that apply across AWS, Azure, Google Cloud, OCI, and IBM Cloud, enabling applications to remain available while simplifying operations and governance.
The following recommendations summarize enterprise best practices for building reliable multi-cloud architectures aligned with the Well-Architected Framework.
Well-Architected Multi-Cloud Reliability Strategy
Reliable cloud platforms are built through consistent architecture, disciplined operations, and continuous improvement. Multi-cloud success depends on standardizing reliability principles rather than implementing different operational models for each provider.
The following strategy board summarizes the key principles for designing reliable enterprise cloud platforms across multiple cloud providers.
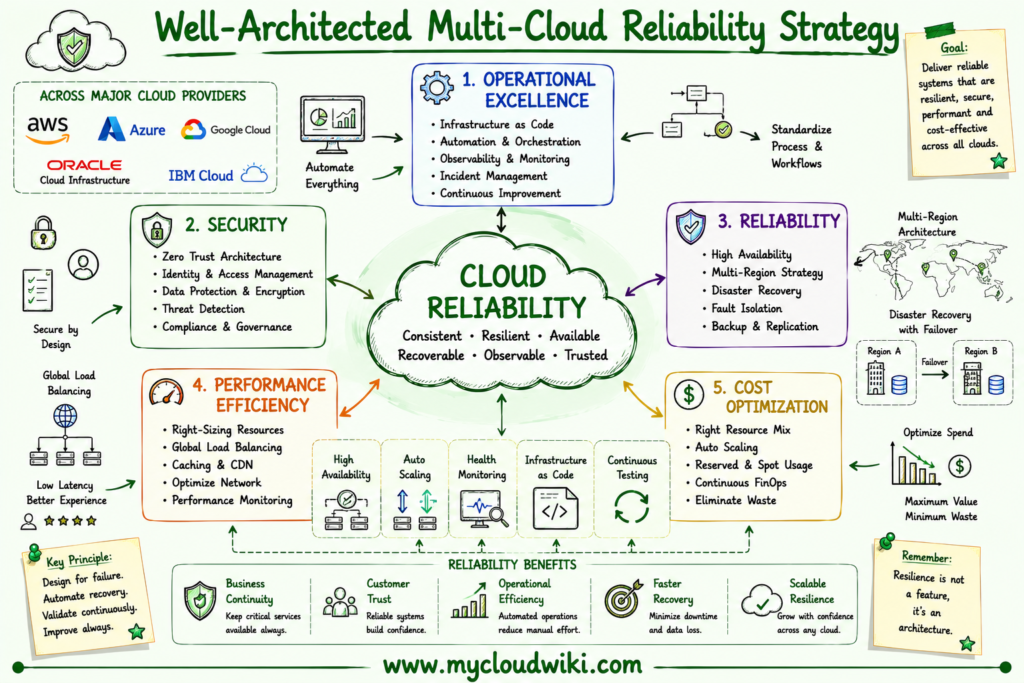
Common Mistakes and Misconceptions
Common Cloud Reliability Mistakes
Architect’s Notebook
Reliable systems are not the result of luck—they are the outcome of thoughtful architecture, disciplined engineering practices, and continuous operational improvement.
Experienced architects assume that failures will occur. Their objective is to design systems that continue serving users, recover quickly, and minimize business impact regardless of which infrastructure component fails.
Rather than depending on individual cloud services, successful organizations standardize resilience principles, automate recovery, continuously monitor application health, and regularly validate disaster recovery capabilities across every cloud provider.
The following notebook captures the most important architectural lessons from this chapter.
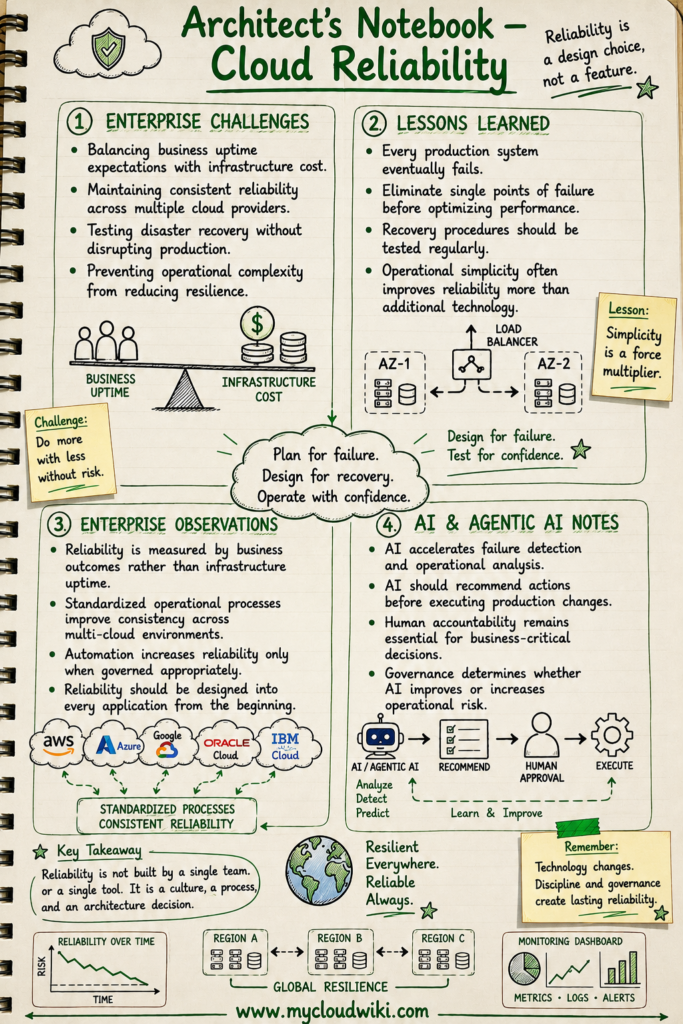
Key Takeaways
- Cloud reliability is achieved by designing systems that continue operating during infrastructure failures rather than attempting to eliminate failures entirely.
- Redundancy, High Availability, fault tolerance, and disaster recovery each address different aspects of enterprise resilience and work together to support business continuity.
- Every major cloud provider offers the building blocks for resilient architectures, but enterprise architects must design and govern reliability consistently across AWS, Azure, Google Cloud, OCI, and IBM Cloud.
- Successful multi-cloud organizations standardize monitoring, automation, disaster recovery, operational procedures, and governance to simplify reliability at scale.
- AI and Agentic AI are transforming reliability engineering through predictive monitoring, intelligent automation, and faster incident response while reinforcing the need for governance and human oversight.
What’s Next
Reliable cloud platforms depend not only on resilient architectures but also on consistent automation. As environments grow across multiple Regions and cloud providers, manually provisioning, configuring, and operating infrastructure becomes inefficient and error-prone.
The next lesson explores how Infrastructure as Code (IaC), automation platforms, CI/CD pipelines, GitOps, and operational workflows help organizations build consistent, repeatable, and scalable cloud environments.
Continue Learning: Cloud Automation Fundamentals explains how automation enables reliable deployments, reduces operational risk, and supports consistent multi-cloud operations across AWS, Azure, Google Cloud, OCI, and IBM Cloud.