{kind=link}
Quick Read
- ✅ Cloud providers organize their global infrastructure into Regions, Availability Zones (AZs), and Edge Locations, enabling organizations to build highly available, low-latency, and resilient applications.
- ✅ Regions provide geographic separation, Availability Zones improve fault tolerance within a region, and Edge Locations bring content and services closer to users for faster performance.
- ✅ Although AWS, Azure, Google Cloud, OCI, and IBM Cloud use different names and implementations, they all follow similar architectural principles for designing global cloud infrastructure.
- ✅ Enterprise architects select regions and availability zones based on business continuity, latency, compliance, data residency, cost, and disaster recovery requirements rather than simply choosing the nearest location.
- ✅ Modern multi-cloud platforms standardize workload placement, networking, security, governance, and disaster recovery across multiple cloud providers while AI increasingly assists with intelligent workload placement and global infrastructure optimization.
Cloud Global Infrastructure as a Foundational Cloud Building Block
In the previous lesson, you learned how Cloud Database Fundamentals enable applications to store, organize, retrieve, and analyze business data across multi-cloud environments. Databases provide the intelligence layer that powers business applications, analytics platforms, and AI solutions.
However, even the most scalable database is only useful if users can reliably access it. Enterprise applications must remain available during hardware failures, regional outages, traffic spikes, and changing business demands. This is where global cloud infrastructure becomes essential.
Cloud providers build large-scale global infrastructures consisting of Regions, Availability Zones, and Edge Locations to ensure applications remain available, resilient, and responsive for users around the world.
Cloud Global Infrastructure Introduction
Every cloud service runs somewhere in the world. Whether you deploy a virtual machine, create a database, store files, or build an AI platform, those resources are hosted inside physical data centers operated by cloud providers.
Rather than operating from a single location, AWS, Azure, Google Cloud, Oracle Cloud Infrastructure (OCI), and IBM Cloud maintain global networks of geographically distributed data centers. These locations are organized into Regions, Availability Zones (AZs), and Edge Locations, each serving a different purpose within the overall cloud architecture.
Understanding this global infrastructure is fundamental because it directly influences:
- Application availability
- Disaster recovery
- Performance and latency
- Regulatory compliance
- Data residency
- Business continuity
- Multi-cloud architecture decisions
For enterprise architects, selecting the right region is no longer simply a deployment decision—it is a business decision that affects customer experience, resilience, compliance, and operational costs.
Every workload deployed into a Region relies on the foundational cloud services you learned earlier, including compute, networking, storage, and databases. If you’d like to review how these building blocks work together, revisit Cloud Building Blocks Explained.
The following illustration shows how cloud providers organize their global infrastructure to deliver reliable services to users around the world.
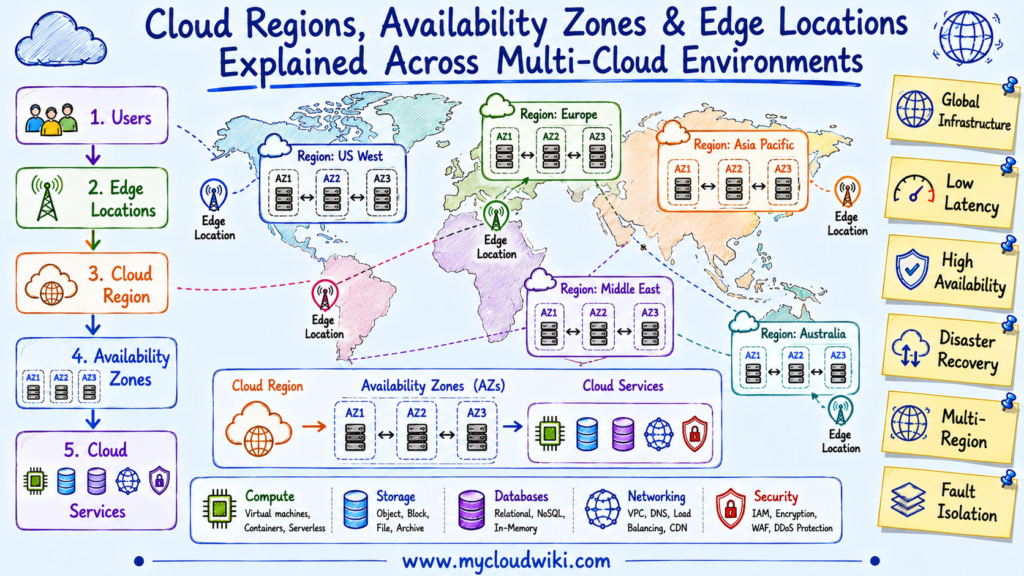
Cloud providers build globally distributed infrastructures so applications can remain available, resilient, and responsive regardless of where users are located. Understanding this physical organization is the foundation for designing highly available and disaster-resilient multi-cloud architectures.
Learning Objectives
After completing this lesson, you will be able to:
- Explain the purpose of Regions, Availability Zones, and Edge Locations.
- Understand how global cloud infrastructure supports high availability, scalability, and low-latency application delivery.
- Compare how AWS, Azure, Google Cloud, OCI, and IBM Cloud organize their global infrastructure.
- Understand how engineers and architects select deployment locations based on business and technical requirements.
- Recognize how global infrastructure influences multi-cloud architecture, disaster recovery, compliance, and AI-driven workload placement.
Core Global Infrastructure Concepts
What Is Global Cloud Infrastructure?
Global cloud infrastructure is the worldwide network of data centers, networking equipment, fiber connectivity, and edge locations that cloud providers use to deliver cloud services. Instead of operating from a single physical location, providers distribute infrastructure across multiple geographic locations to improve resilience, performance, and business continuity.
Although every cloud provider has its own terminology and deployment model, they all share a common architectural approach:
- Regions provide geographic separation.
- Availability Zones provide fault isolation within a Region.
- Edge Locations bring services closer to end users.
- High-speed private networks connect these locations together.
This layered infrastructure enables organizations to build applications that continue operating even when individual servers, data centers, or entire locations experience failures.
As enterprise organizations expand globally, selecting the appropriate deployment locations becomes an important architectural decision that balances performance, availability, compliance, operational complexity, and cost.
Reliable global connectivity depends on robust cloud networking. If you’d like to understand how traffic flows between users and cloud resources, explore Cloud Networking Fundamentals.
Key Characteristics of Global Cloud Infrastructure
Although implementations differ across cloud providers, modern global infrastructures share several common characteristics:
- Geographically distributed Regions around the world.
- Multiple independent Availability Zones within each Region.
- Edge Locations positioned close to users.
- High-speed private backbone networks connecting infrastructure.
- Built-in redundancy for improved resilience.
- Low-latency connectivity for global applications.
- Support for disaster recovery and business continuity.
- Scalable infrastructure that expands as business demand grows.
These capabilities allow organizations to design applications that remain available, secure, and responsive while serving users across multiple countries and cloud providers.
How Global Cloud Infrastructure Works
When a user accesses a cloud application, the request is typically routed to the nearest Edge Location or network entry point. Static content may be served immediately from the edge, while dynamic requests continue through the provider’s private backbone network to the appropriate Region.
Within the selected Region, workloads are usually distributed across multiple Availability Zones. This ensures that if one Availability Zone experiences an infrastructure failure, applications can continue operating from another zone with minimal disruption.
In enterprise multi-cloud environments, architects often extend this design across multiple Regions and even multiple cloud providers to improve resilience, reduce latency, support regulatory requirements, and strengthen disaster recovery capabilities.
Designing resilient applications across Regions and Availability Zones is the foundation of business continuity. You’ll explore these design principles in detail in Cloud Reliability & High Availability Fundamentals.
The following diagram illustrates how user requests travel through Edge Locations, Regions, and Availability Zones before reaching cloud services.
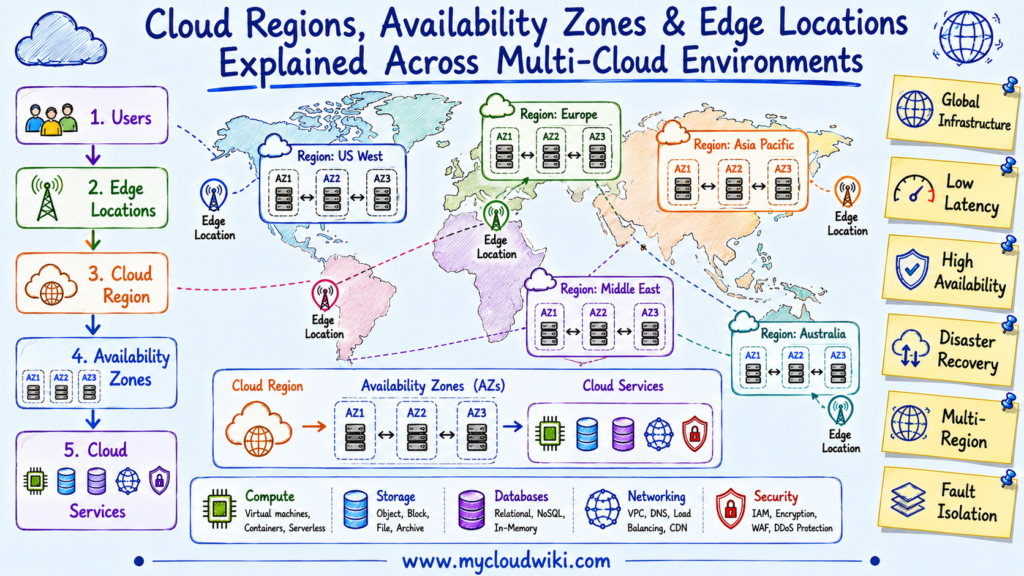
Managed global infrastructure allows cloud providers to deliver resilient, high-performance services around the world. By understanding how Regions, Availability Zones, and Edge Locations work together, engineers and architects can design applications that remain available, scalable, and responsive across enterprise multi-cloud environments.
Understanding Regions, Availability Zones and Edge Locations
Although these terms are often used together, they represent different layers of a cloud provider’s global infrastructure. Understanding how they work together is essential for designing scalable, resilient, and high-performing enterprise applications.
Think of them as a hierarchy:
- Regions provide geographic separation.
- Availability Zones provide fault isolation within a Region.
- Edge Locations bring services closer to users.
- Together, they create a global platform capable of supporting enterprise applications at massive scale.
Cloud Regions
A Cloud Region is a geographically separate area where a cloud provider operates one or more data centers. Regions allow organizations to deploy workloads closer to their users while meeting business, regulatory, and disaster recovery requirements.
Regions are designed to operate independently from one another. This isolation allows organizations to continue operating even if another geographic location experiences a large-scale outage.
Organizations typically choose Regions based on:
- User proximity and application latency.
- Regulatory and compliance requirements.
- Data residency laws.
- Disaster recovery strategy.
- Service availability.
- Business continuity objectives.
Rather than selecting the nearest Region by default, enterprise architects evaluate multiple business and technical factors before deciding where workloads should reside.
Availability Zones (AZs)
An Availability Zone (AZ) is an isolated data center—or group of closely connected data centers—within a Region. Each Availability Zone has independent power, cooling, and networking infrastructure while remaining connected to other Availability Zones through high-speed private networks.
This design enables applications to continue operating even if one Availability Zone becomes unavailable.
Enterprise applications commonly distribute workloads across multiple Availability Zones to improve:
- High availability.
- Fault tolerance.
- Automatic failover.
- Maintenance flexibility.
- Operational resilience.
Most production workloads should be designed to use multiple Availability Zones whenever possible.
Architect’s Tip: Deploying every application component into a single Availability Zone creates a single point of failure. Designing for multiple Availability Zones is one of the simplest ways to improve application resilience.
Edge Locations
An Edge Location is a network site positioned closer to end users than a Cloud Region. Instead of hosting complete cloud environments, Edge Locations provide services that reduce latency and improve user experience by processing requests closer to where users are located.
Edge Locations commonly support:
- Content delivery (CDN)
- DNS resolution
- Web application acceleration
- Security filtering
- API acceleration
- Edge computing
For example, when a user requests a static image or video, it can often be delivered directly from a nearby Edge Location instead of traveling all the way to the application’s primary Region.
This significantly reduces latency while improving application performance for users around the world.
Local Zones
Some workloads require extremely low latency but cannot be deployed entirely at Edge Locations. To address these requirements, cloud providers offer Local Zones, which extend selected cloud services closer to major metropolitan areas.
Local Zones are commonly used for:
- Media rendering
- Video production
- Gaming
- Financial trading
- Healthcare imaging
- Manufacturing systems
Unlike Edge Locations, Local Zones can host application workloads while remaining connected to their parent Region.
Wavelength Zones
As 5G networks continue to expand, cloud providers are integrating cloud services directly into telecommunications infrastructure through Wavelength Zones.
These environments allow applications requiring ultra-low latency to execute closer to mobile users.
Typical workloads include:
- Autonomous vehicles
- Augmented Reality (AR)
- Virtual Reality (VR)
- Smart factories
- Connected healthcare
- Industrial IoT
For most organizations, Wavelength Zones represent a specialized deployment option rather than a standard enterprise architecture requirement.
The following illustration compares the major components of a cloud provider’s global infrastructure and shows how each layer contributes to application performance, availability, and resilience.
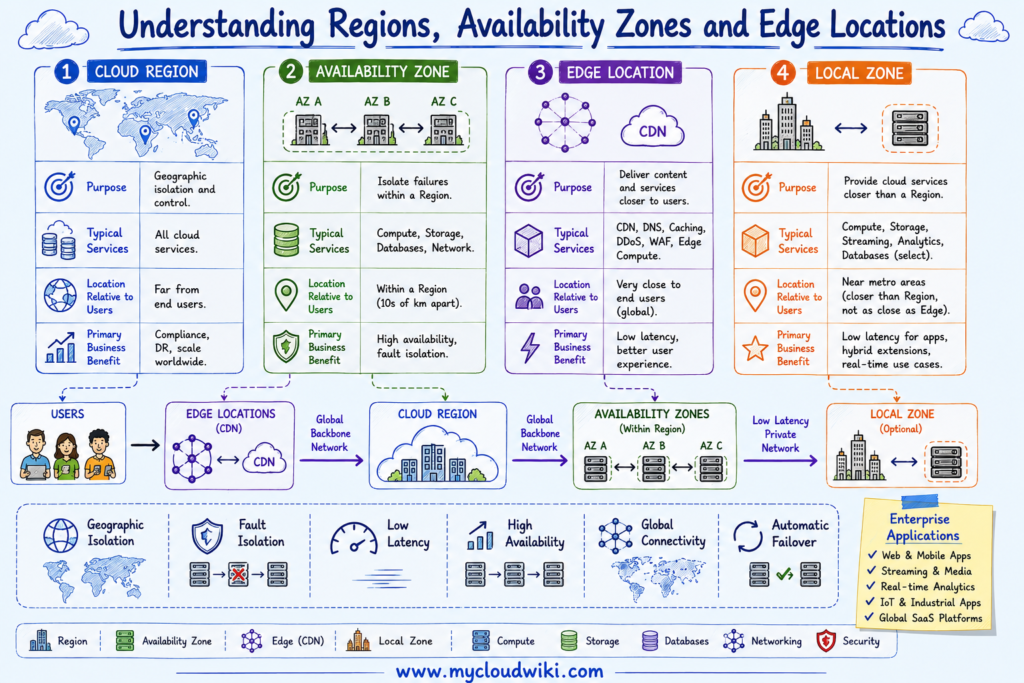
Regions, Availability Zones, Edge Locations, and Local Zones each solve different infrastructure challenges. Together, they provide the global foundation that enables cloud providers to deliver secure, resilient, and high-performance services worldwide.
How Enterprise Applications Use Global Infrastructure
Enterprise applications rarely operate from a single location. Instead, they are distributed across multiple infrastructure layers to improve performance, resilience, and user experience while meeting business and regulatory requirements.
A typical global application might use:
- Multiple Regions for disaster recovery and business continuity.
- Multiple Availability Zones within each Region for high availability.
- Edge Locations to accelerate content delivery.
- Local Zones for ultra-low-latency workloads in major metropolitan areas.
- Private backbone networks to securely connect global infrastructure.
This layered architecture allows organizations to continue serving users even during infrastructure failures while maintaining consistent application performance around the world.
Continue Learning: Cloud Reliability & High Availability Fundamentals explores how architects design applications that continue operating during server, data center, Availability Zone, and even regional failures.
The following architecture demonstrates how enterprise applications use Regions, Availability Zones, and Edge Locations together to deliver highly available global services.
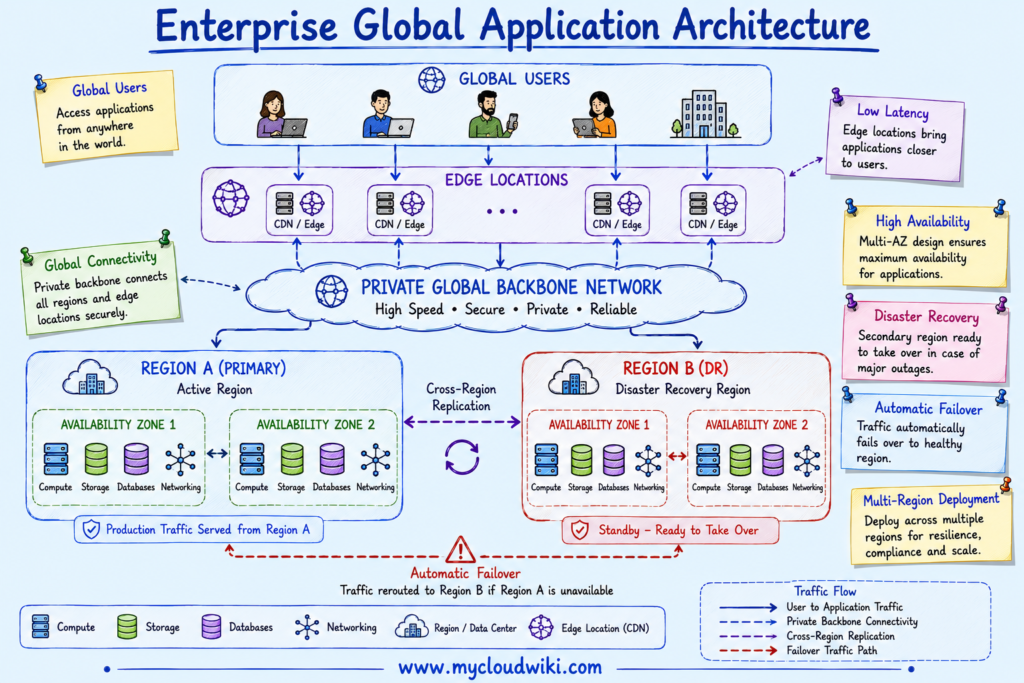
How to Choose Regions and Availability Zones
Selecting deployment locations involves much more than choosing the closest Region. Enterprise architects evaluate technical, business, regulatory, and operational requirements before deciding where workloads should run.
Common decision factors include:
- Geographic proximity to users.
- Application latency requirements.
- Regulatory compliance and data residency.
- Business continuity objectives.
- Disaster recovery strategy.
- Service availability within the Region.
- Network connectivity.
- Operational costs.
- Future business expansion.
Successful multi-cloud organizations apply consistent workload placement principles across AWS, Azure, Google Cloud, OCI, and IBM Cloud rather than making deployment decisions independently for each provider.
Architect’s Tip: Choose Regions based on business requirements first, then optimize for latency and cost. A slightly higher latency is often acceptable if it helps meet compliance, resilience, or disaster recovery objectives.
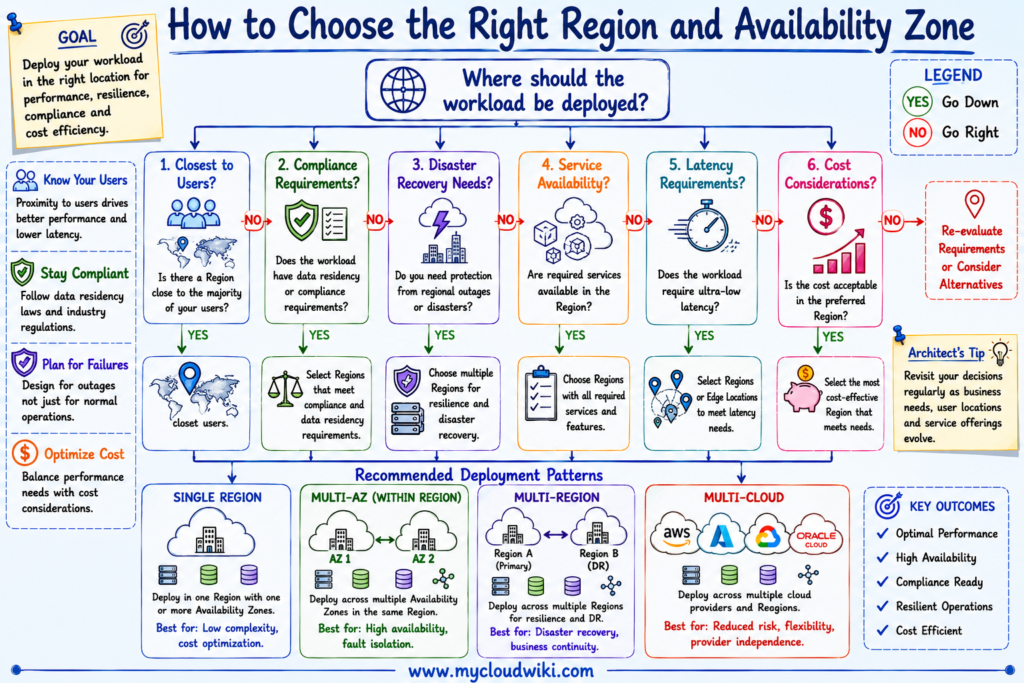
The following decision matrix summarizes the most important factors to consider when selecting Regions and Availability Zones for enterprise workloads.
Choosing the Right Region and Availability Zone
The following decision tree illustrates how architects evaluate business and technical requirements when selecting deployment Regions and Availability Zones.
Global Infrastructure Across Major Cloud Providers
Although every cloud provider organizes its infrastructure differently, they all follow the same architectural principles. Each provider builds geographically distributed Regions, isolates workloads across Availability Zones or equivalent fault domains, and operates edge infrastructure to improve application performance for users worldwide.
For cloud engineers, learning these concepts makes it easier to work across multiple cloud providers. For enterprise architects, understanding the similarities enables the design of consistent deployment, networking, disaster recovery, and governance strategies without becoming dependent on provider-specific terminology.
Rather than memorizing provider-specific names, focus on understanding the common architecture:
- Regions provide geographic separation.
- Availability Zones provide fault isolation.
- Edge infrastructure reduces latency.
- Private backbone networks connect global resources.
- Global infrastructure enables business continuity.
Architect’s Tip: Learn the architecture first and the service names second. Once you understand the concepts, mapping them to AWS, Azure, Google Cloud, OCI, or IBM Cloud becomes straightforward.
The following comparison maps the global infrastructure concepts across the five major cloud providers.
Global Infrastructure Across Major Cloud Providers
Although the terminology differs slightly, the design philosophy is remarkably consistent. Every major cloud provider separates infrastructure geographically, isolates failures within Regions, and extends services closer to users through edge infrastructure.
The following illustration compares how AWS, Azure, Google Cloud, OCI, and IBM Cloud organize their global infrastructure while highlighting the common architectural building blocks.
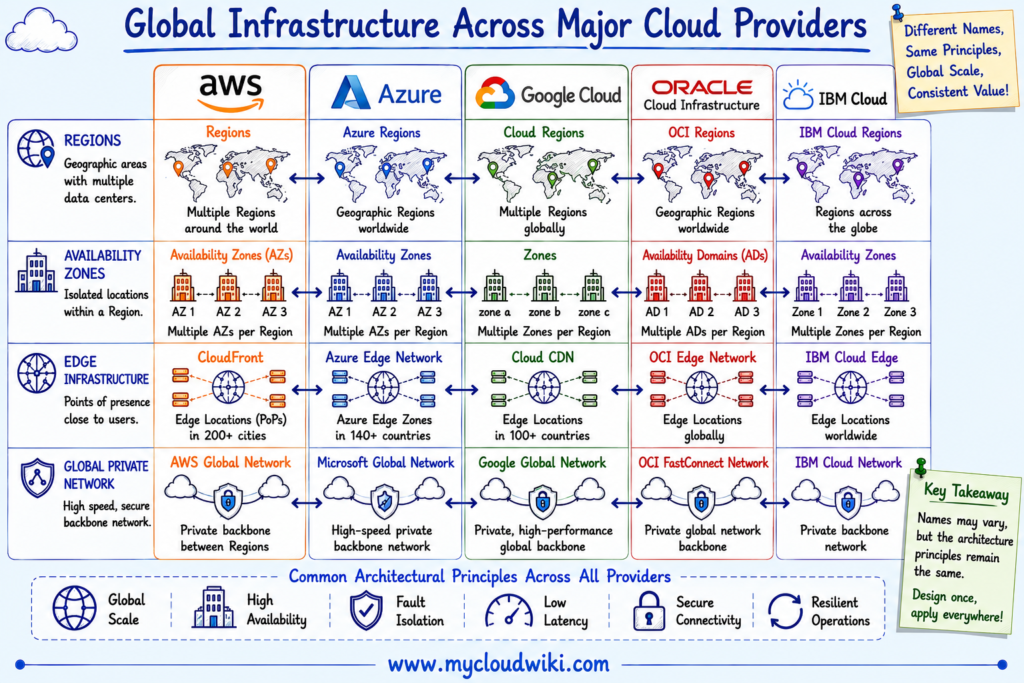
Enterprise architects build cloud strategies around common infrastructure concepts rather than provider-specific terminology. This approach simplifies multi-cloud adoption and enables consistent governance across different cloud platforms.
Cloud Global Infrastructure Through the Engineer and Architect Lens
Cloud engineers and enterprise architects both work with Regions, Availability Zones, and Edge Locations, but they approach global infrastructure from different perspectives. Engineers focus on deploying and operating workloads, while architects design global infrastructure strategies that support long-term business objectives.
Engineer Perspective
Cloud engineers implement the infrastructure required to keep applications available, secure, and performant across Regions and Availability Zones.
Typical responsibilities include:
- Deploy workloads into the appropriate Regions.
- Configure multi-Availability Zone deployments.
- Implement load balancing and traffic routing.
- Configure disaster recovery replication.
- Deploy content delivery services.
- Monitor regional health and application performance.
- Troubleshoot connectivity and latency issues.
- Automate deployments using Infrastructure as Code.
The engineer’s objective is to ensure applications are reliable, scalable, and operational.
Architect Perspective
Enterprise architects define how applications should be distributed globally while balancing resilience, compliance, performance, and operational complexity.
Typical responsibilities include:
- Define regional deployment strategies.
- Select multi-region architectures.
- Design disaster recovery solutions.
- Establish workload placement standards.
- Define data residency policies.
- Standardize networking and connectivity.
- Optimize global infrastructure costs.
- Establish governance across multiple cloud providers.
Rather than focusing on individual deployments, architects create enterprise standards that engineering teams can apply consistently across AWS, Azure, Google Cloud, OCI, and IBM Cloud.
Continue Learning: Build Your First Multi-Cloud Architecture Mental Model demonstrates how these infrastructure decisions fit into an enterprise-wide cloud architecture.
The following illustration compares how engineers and architects approach global cloud infrastructure from operational and strategic perspectives.
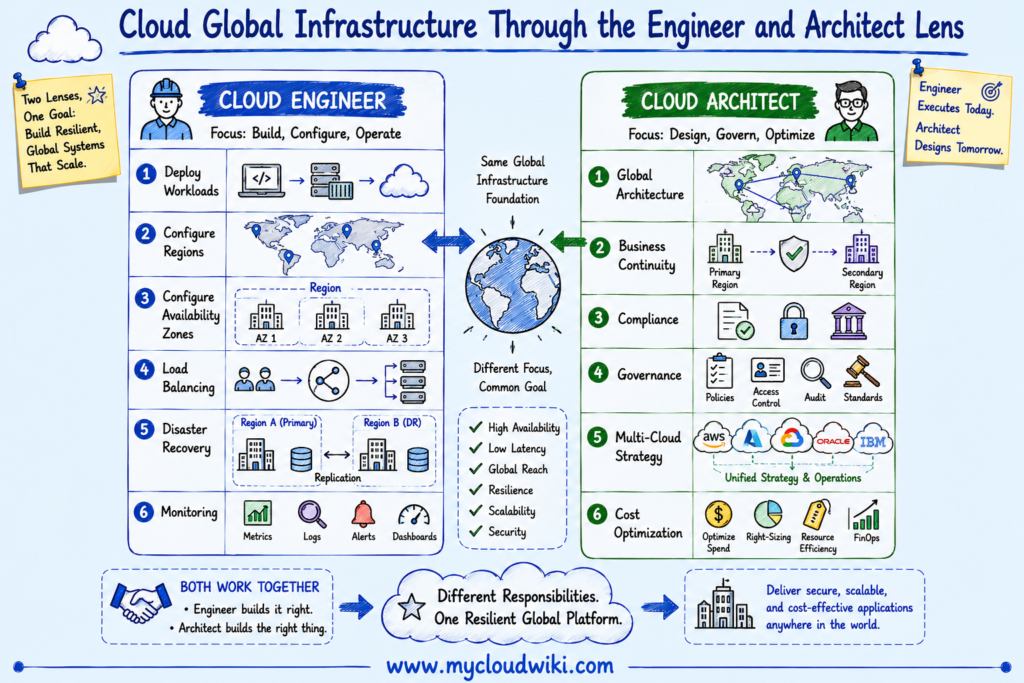
Cloud engineers and architects share the same goal—building resilient, high-performing cloud platforms—but contribute in different ways. Engineers implement and operate global infrastructure, while architects define the enterprise standards that ensure applications remain scalable, compliant, and resilient across multiple cloud providers.
Multi-Cloud Reality Check
Operating across multiple cloud providers introduces additional complexity because each provider offers different geographic coverage, service availability, networking architectures, and deployment options. Organizations that treat each cloud independently often create inconsistent operational practices that become difficult to manage at scale.
Successful multi-cloud organizations focus on standardization rather than uniformity. Instead of forcing every provider to look identical, they establish consistent architectural principles that can be applied regardless of where workloads run.
Common multi-cloud challenges include:
- Different Region naming conventions.
- Varying service availability by Region.
- Different networking architectures.
- Regulatory and data residency requirements.
- Cross-cloud latency considerations.
- Operational complexity across providers.
- Consistent governance and security.
Rather than solving these challenges independently within each cloud, enterprise architects define organization-wide standards for workload placement, networking, disaster recovery, security, and compliance.
Cloud Global Infrastructure in Multi-Cloud Environments
Enterprise organizations rarely depend on a single Region or a single cloud provider. Instead, they distribute applications across multiple geographic locations to improve resilience, reduce latency, and support business continuity.
A typical enterprise global deployment might include:
- Primary production workloads in one Region.
- Secondary disaster recovery deployments in another Region.
- Edge infrastructure serving users worldwide.
- Multi-cloud connectivity between providers.
- Centralized identity and governance.
- Unified monitoring and observability.
- Common security and compliance policies.
This architecture enables organizations to maintain consistent operations while allowing individual business units to deploy workloads in the Regions and cloud providers that best meet their technical and regulatory requirements.
Architect’s Tip: Design your workload placement strategy once and apply it consistently across every cloud provider. Consistency in governance delivers far greater long-term value than optimizing each cloud independently.
The following architecture illustrates how enterprise organizations build globally distributed, multi-cloud platforms using standardized governance and operational practices.
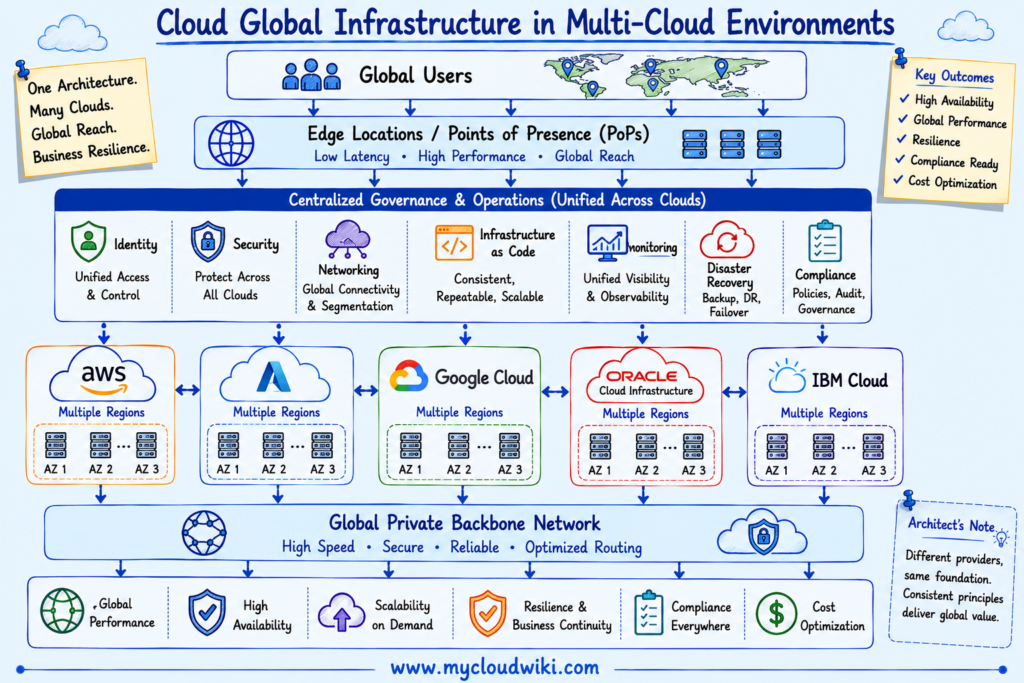
Cloud Global Infrastructure with Agentic AI
Managing global cloud infrastructure has become increasingly complex as organizations expand across multiple Regions, Availability Zones, cloud providers, and geographic markets. Engineers must continuously monitor application health, optimize workload placement, respond to failures, and maintain compliance while balancing performance and cost.
Artificial Intelligence is helping simplify these operational challenges by analyzing infrastructure telemetry, identifying anomalies, recommending optimizations, and assisting engineers with day-to-day operations.
Agentic AI extends these capabilities further by allowing AI agents to perform operational workflows under defined governance policies. Rather than simply recommending an action, an AI agent can execute approved workflows such as workload placement, failover, capacity scaling, or disaster recovery while maintaining human oversight and auditability.
Common enterprise use cases include:
- Predicting regional capacity requirements.
- Recommending optimal deployment Regions.
- Detecting regional service degradation.
- Automating disaster recovery runbooks.
- Optimizing global traffic routing.
- Forecasting infrastructure costs.
- Identifying compliance risks across Regions.
- Assisting engineers during operational incidents.
Although AI improves operational efficiency, enterprise architects remain responsible for defining governance policies, approval workflows, security boundaries, and business continuity strategies.
Architect’s Tip: AI should assist with infrastructure operations—not replace architectural decision-making. Human oversight remains essential for workload placement, compliance, disaster recovery, and governance.
The following illustration shows how AI and Agentic AI help organizations manage global cloud infrastructure while operating within enterprise governance and security controls.
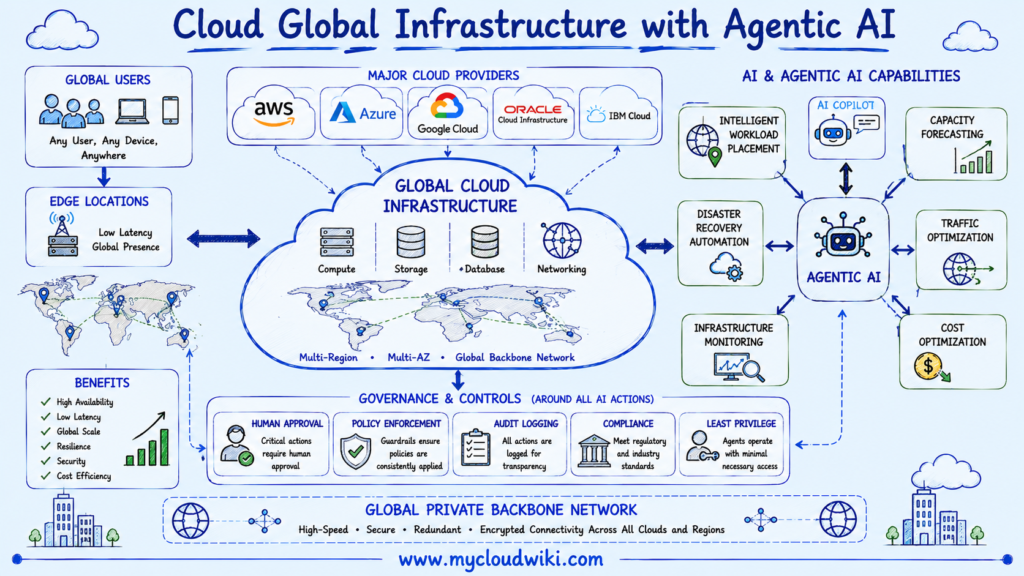
AI is becoming an operational partner for cloud engineers by helping manage increasingly complex global infrastructures. However, enterprise governance, security, and business continuity decisions continue to require human accountability.
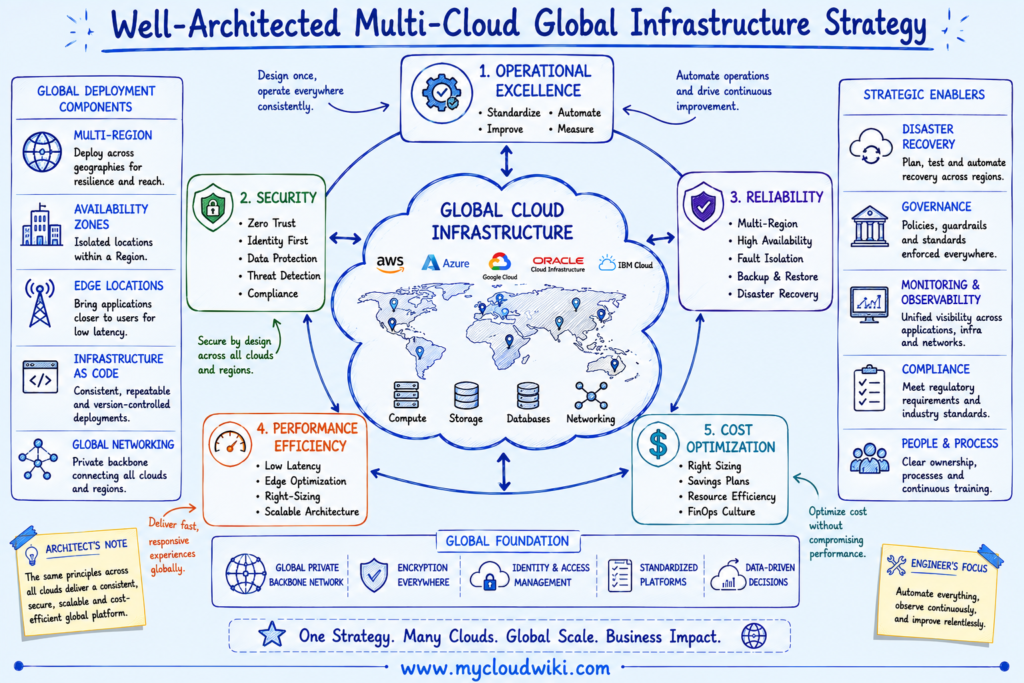
Well-Architected Multi-Cloud Global Infrastructure Strategy
Designing enterprise global infrastructure requires balancing resilience, performance, compliance, operational simplicity, and cost across multiple cloud providers. Rather than optimizing each provider independently, organizations should establish consistent infrastructure standards that apply across AWS, Azure, Google Cloud, OCI, and IBM Cloud.
The following recommendations summarize best practices for designing and operating global cloud infrastructure using a multi-cloud approach aligned with the Well-Architected Framework.
Well-Architected Multi-Cloud Global Infrastructure Strategy
Consistent architecture, governance, and operational practices enable organizations to build resilient global platforms while controlling complexity across multiple cloud providers.
The following strategy board summarizes the key architectural principles for designing global cloud infrastructure across enterprise multi-cloud environments.
Common Mistakes and Misconceptions
Common Global Cloud Infrastructure Mistakes
Architect’s Notebook
Enterprise architects rarely begin by selecting a Region. Instead, they first understand where users are located, which regulations apply, how resilient the application must be, and what business continuity objectives need to be achieved.
Successful global infrastructure strategies standardize deployment principles, governance, networking, and disaster recovery across every cloud provider while allowing individual workloads to be deployed where they deliver the greatest business value.
The following notebook summarizes the most important architectural lessons from this chapter.

Key Takeaways
- Cloud providers organize their infrastructure into Regions, Availability Zones, and Edge Locations to deliver resilient, scalable, and low-latency services worldwide.
- Although terminology differs across AWS, Azure, Google Cloud, OCI, and IBM Cloud, the underlying architectural principles remain consistent.
- Enterprise architects select deployment locations based on business continuity, compliance, performance, resilience, and governance—not just geographic proximity.
- Successful multi-cloud organizations standardize workload placement, networking, security, disaster recovery, and governance across providers while allowing flexibility for individual workloads.
- AI and Agentic AI are improving global infrastructure operations through intelligent automation, workload optimization, and operational assistance while reinforcing the importance of governance and human oversight.
What’s Next
Understanding global infrastructure is only the first step toward building resilient cloud applications. The next lesson explores how enterprise workloads remain operational during failures by using redundancy, fault tolerance, backup strategies, and disaster recovery across multiple Regions and Availability Zones.
Continue Learning: Cloud Reliability & High Availability Fundamentals will show you how engineers and architects design cloud platforms that continue operating during infrastructure failures, planned maintenance, and unexpected outages across multi-cloud environments.